 分类算法的评价指标
分类算法的评价指标
分类评估方法主要功能是用来评估分类算法的好坏,而评估一个分类器算法的好坏又包括许多项指标。了解各种评估方法,在实际应用中选择正确的评估方法是十分重要的。
- 几个常用术语 这里首先介绍几个常见的模型评价术语,现在假设我们的分类目标只有两类,计为正例(positive)和负例(negative)分别是:
True positives(TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数;
False positives(FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
True negatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
表2-2 四个术语的混淆矩阵
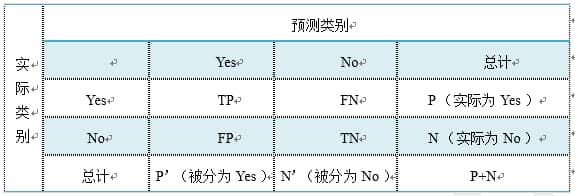
表2-2是这四个术语的混淆矩阵,做以下说明:
- P=TP+FN表示实际为正例的样本个数。
- True、False描述的是分类器是否判断正确。
- Positive、Negative是分类器的分类结果,如果正例计为1、负例计为-1,即positive=1、negative=-1。用1表示True,-1表示False,那么实际的类标=TF*PN,TF为true或false,PN为positive或negative。
- 例如True positives(TP)的实际类标=11=1为正例,False positives(FP)的实际类标=(-1)1=-1为负例,False negatives(FN)的实际类标=(-1)(-1)=1为正例,True negatives(TN)的实际类标=1*(-1)=-1为负例。
评价指标
- 正确率(accuracy)
正确率是我们最常见的评价指标,accuracy = (TP+TN)/(P+N),正确率是被分对的样本数在所有样本数中的占比,通常来说,正确率越高,分类器越好。Copy to clipboardErrorCopied1- 错误率(error rate)
错误率则与正确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(P+N),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate。Copy to clipboardErrorCopied1- 灵敏度(sensitivity)
sensitivity = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力。Copy to clipboardErrorCopied1- 特异性(specificity)
specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力。Copy to clipboardErrorCopied1- 精度(precision)
precision=TP/(TP+FP),精度是精确性的度量,表示被分为正例的示例中实际为正例的比例。Copy to clipboardErrorCopied1- 召回率(recall)
召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitivity,可以看到召回率与灵敏度是一样的。Copy to clipboardErrorCopied1- 其他评价指标
计算速度:分类器训练和预测需要的时间; 鲁棒性:处理缺失值和异常值的能力; 可扩展性:处理大数据集的能力; 可解释性:分类器的预测标准的可理解性,像决策树产生的规则就是很容易理解的,而神经网络的一堆参数就不好理解,我们只好把它看成一个黑盒子。Copy to clipboardErrorCopied1
2
3
4- 精度和召回率反映了分类器分类性能的两个方面。如果综合考虑查准率与查全率,可以得到新的评价指标F1-score,也称为综合分类率:
为了综合多个类别的分类情况,评测系统整体性能,经常采用的还有微平均F1(micro-averaging)和宏平均F1(macro-averaging )两种指标。 (1)宏平均F1与微平均F1是以两种不同的平均方式求的全局F1指标。 (2)宏平均F1的计算方法先对每个类别单独计算F1值,再取这些F1值的算术平均值作为全局指标。 (3)微平均F1的计算方法是先累加计算各个类别的a、b、c、d的值,再由这些值求出F1值。 (4)由两种平均F1的计算方式不难看出,宏平均F1平等对待每一个类别,所以它的值主要受到稀有类别的影响,而微平均F1平等考虑文档集中的每一个文档,所以它的值受到常见类别的影响比较大。Copy to clipboardErrorCopied1
2
3
4
5
6
7
8
9ROC曲线和PR曲线
如图2-3,ROC曲线是(Receiver Operating Characteristic Curve,受试者工作特征曲线)的简称,是以灵敏度(真阳性率)为纵坐标,以1减去特异性(假阳性率)为横坐标绘制的性能评价曲线。可以将不同模型对同一数据集的ROC曲线绘制在同一笛卡尔坐标系中,ROC曲线越靠近左上角,说明其对应模型越可靠。也可以通过ROC曲线下面的面积(Area Under Curve, AUC)来评价模型,AUC越大,模型越可靠。Copy to clipboardErrorCopied1
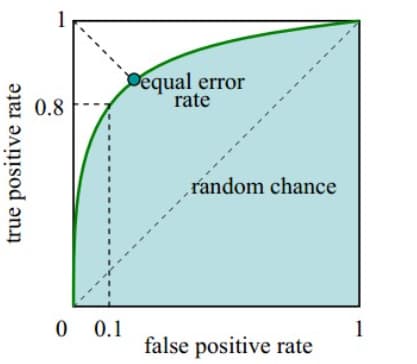
图2-3 ROC曲线
PR曲线是Precision Recall Curve的简称,描述的是precision和recall之间的关系,以recall为横坐标,precision为纵坐标绘制的曲线。该曲线的所对应的面积AUC实际上是目标检测中常用的评价指标平均精度(Average Precision, AP)。AP越高,说明模型性能越好。
编辑 (opens new window)
上次更新: 2024/05/30, 07:49:34