 TensorDataset、Dataset和DataLoader
TensorDataset、Dataset和DataLoader
# TensorDataset类
TensorDataset能够用来对tensor进行打包,包装成Dataset
torch_dataset = Data.TensorDataset(x, y)
1
# Dataset类
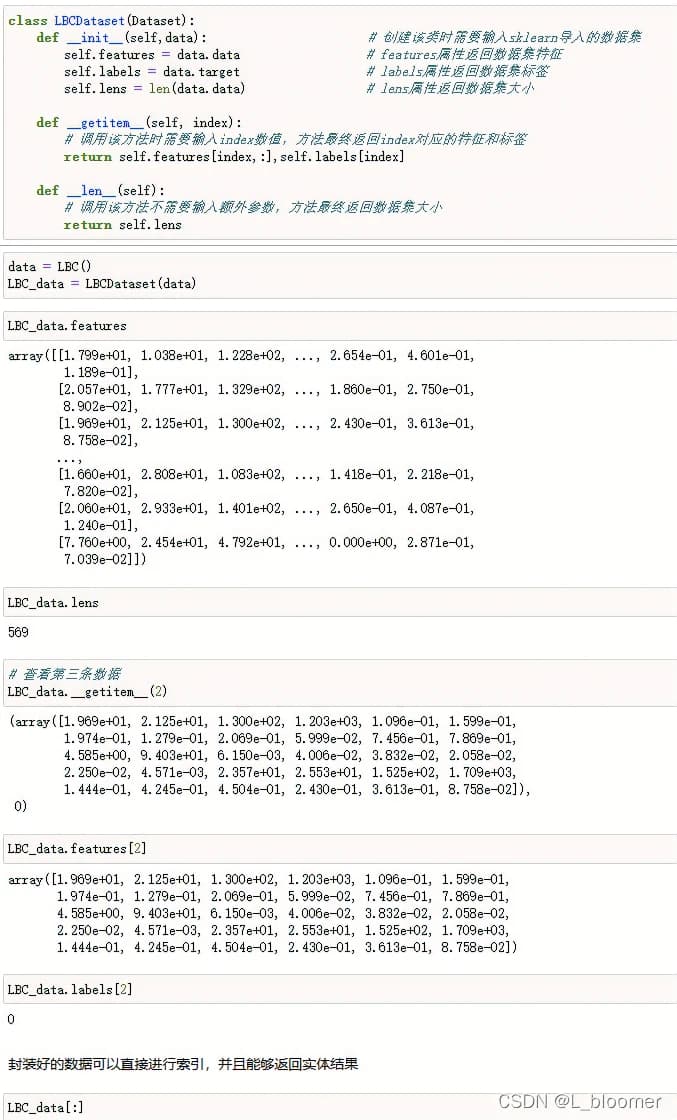
pytorch中所有的数据都是Dataset的子类,我们在使用pytorch生成训练数据时,可以创建一个继承Dataset类的数据类来方便我们使用数据
在创建Dataset子类时,需要重写getitem方法和len方法,其中getitem方法返回输入索引后对应的特征和标签,而len方法则返回数据集的总数据个数
在init初始化过程中,我们也可以输入可代表数据集基本属性的相关内容,包括数据集的特征、标签、大小等信息
示例:
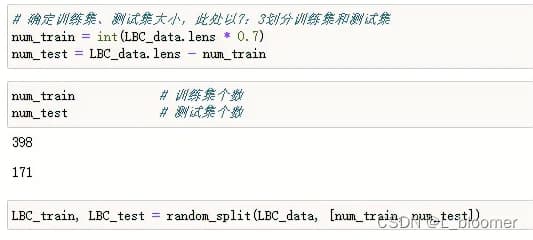
另外,我们能够使用在torch.utils.data中的random_split函数去切分数据集
此时切分的结果是一个映射式的对象,只有dataset和indices两个属性,其中dataset属性用于查看原数据集对象,indices属性用于查看切分后数据集的每一条数据的index(序号)
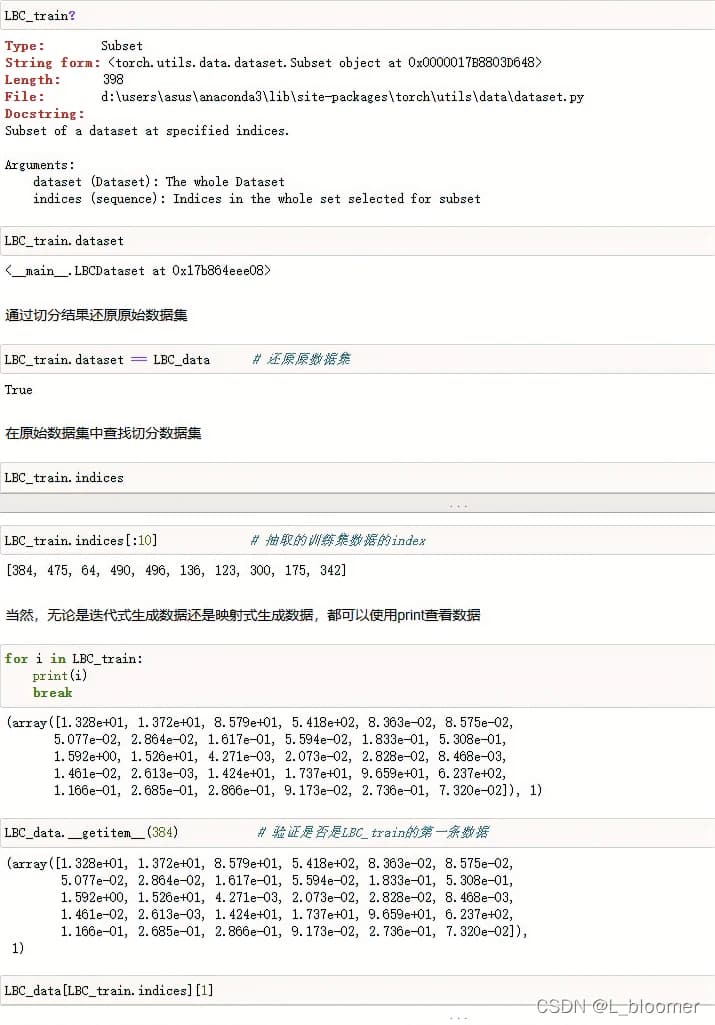
此外,如果想从已建立的Dataset中划分训练集测试集,可以使用Subset进行拆分,示例如下:
train_dataset = torch.utils.data.Subset(dataset, range(int(split_rate * dataset.lens)))
test_dataset = torch.utils.data.Subset(dataset, range(int(split_rate * dataset.lens), dataset.lens))
1
2
2
# DataLoader类
DataLoader类负责进行数据转化,将一般数据状态转换为“可建模”的状态,即不仅包含数据原始的数据信息,还包含数据处理方法信息,如调用几个线程进行训练、分多少批次等
原型:
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=2, persistent_workers=False)
1
几个重要参数:
- batch_size:每次迭代输入多少数据
- shuffle:是否需要先打乱顺序然后再进行小批量的切分,一般训练集需要乱序,而测试集乱序没有意义
- num_worker:启动多少线程进行计算
DataLoader的使用需要搭配迭代器来使用,for i, (input, target) in enumerate(data_loader)或next(iter(data_loader))都可以返回数据和标签
编辑 (opens new window)
上次更新: 2024/05/30, 07:49:34