 半监督学习经典方法 Π-model、Mean Teacher
半监督学习经典方法 Π-model、Mean Teacher
# Π-model与Temporal ensembling
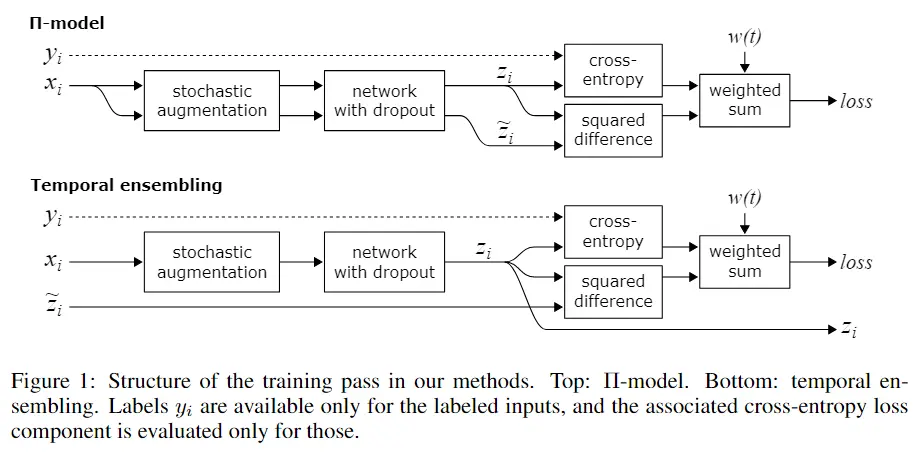
Π-model将标记数据与未标记数据一起输入,每个数据重复输入两次,得到的预测向量过两个损失。其中第一个为标准交叉熵损失,只作用于有标注数据,计算分类损失,另一个为均方误差损失,作用于所有数据,它在重复输入两次得到的两个预测向量之间计算损失,两个损失相加得到最终loss。两次输入之间的差异由增强与dropout带来。
Temporal ensembling将两个损失的评估分成两个独立的阶段:首先在不更新权重θ的情况下对训练集进行分类,然后在不同的增强和dropout下在相同的输入上训练网络,只使用刚刚获得的预测作为无监督损失组件的目标。由于以这种方式获得的训练目标是基于对网络的单一评估,因此它们可以预期是嘈杂的。时间集成通过将多个先前网络评估的预测聚合到集成预测中来缓解这个问题。(分类损失+当前预测向量与之前输出的所有预测向量的聚合之间的损失)
Temporal ensembling与Π-model的不同在于它在每个训练步中只评估网络一次(即只进行一次正向过程),且它的预测向量比较来源于先前的所有循环输出,计算公式如下:
# Mean Teacher
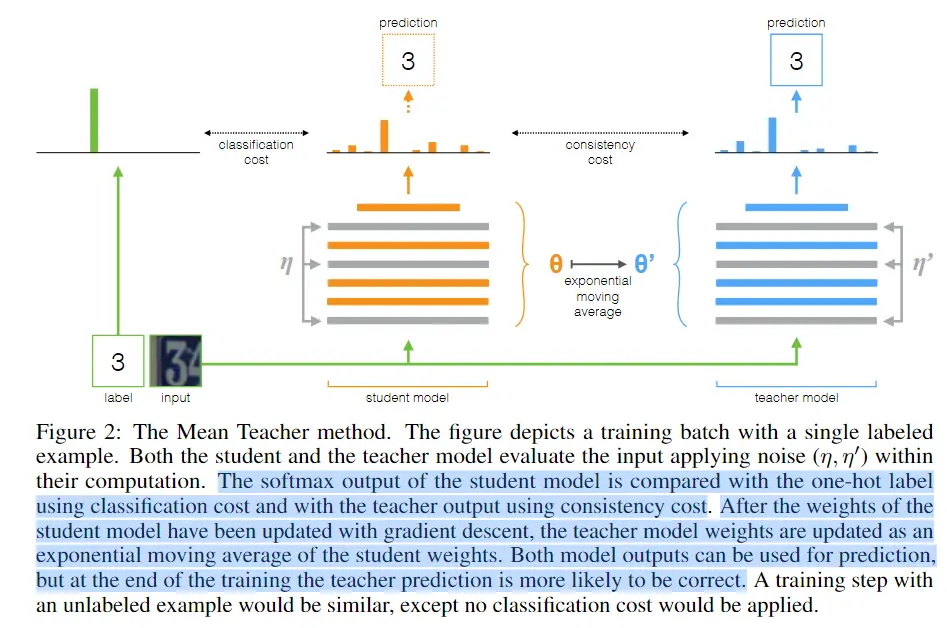
有两个一致的模型,分别为学生模型与教师模型,学生模型通过正常的反向传播更新参数,教师模型通过学生模型权重的指数移动平均进行更新。
学生模型接受两个损失,一个是普通的分类损失,另一个是与教师模型输出的一致性损失,一致性损失的计算如下:
这里