计算机视觉对比学习综述
计算机视觉对比学习综述
# 1. Unsupervised Feature Learning via Non-Parametric Instance Discrimination
# 动机
在用一个已经训练好的有监督分类器对豹子的图片进行分类时,豹类图片的分数较高,而其他物品的分数很低,因此作者提出一种无监督学习方法——个体判别,将每一个图片看成是一个类别,理想目标是将每一个图片区分开来。

# 方法
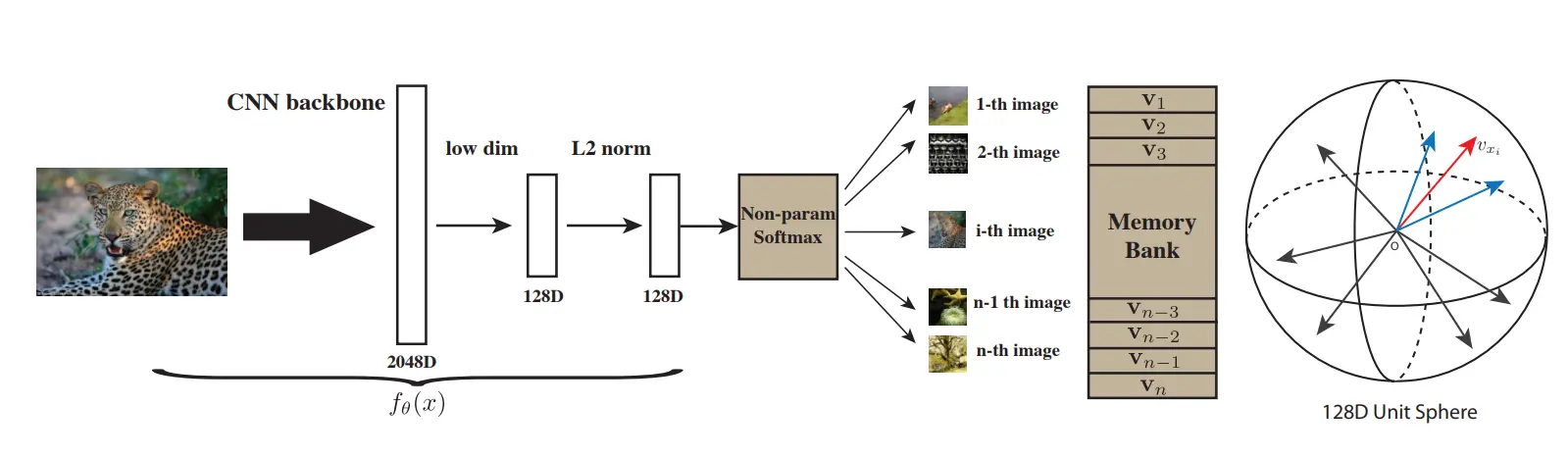
首先使用CNN提取每个图像的特征,并形成一个Memory Bank字典,对每个训练样本,使用KNN,在字典中查找最相似的样本作为正样本,并随机挑选一些其它的样本作为负样本,在编码器进行梯度更新之后,对这次使用到的样本用新的编码器生成新的特征并更新Memory Bank字典
将选出的正负样本组合为一个分类问题,使用NCE损失来优化模型,具体而言,对于每个正样本,NPID会计算它与所有负样本之间的相似度得分,然后使用softmax函数将这些得分转换为概率分布。最终,使用交叉熵损失函数来最小化正样本和负样本之间的差异。
经过多次迭代之后,模型能够产生更加紧密的正样本聚类和更分散的负样本,从而得到更好的特征表示。
# 2. Unsupervised Embedding Learning via Invariant and Spreading Instance Feature
# 思想
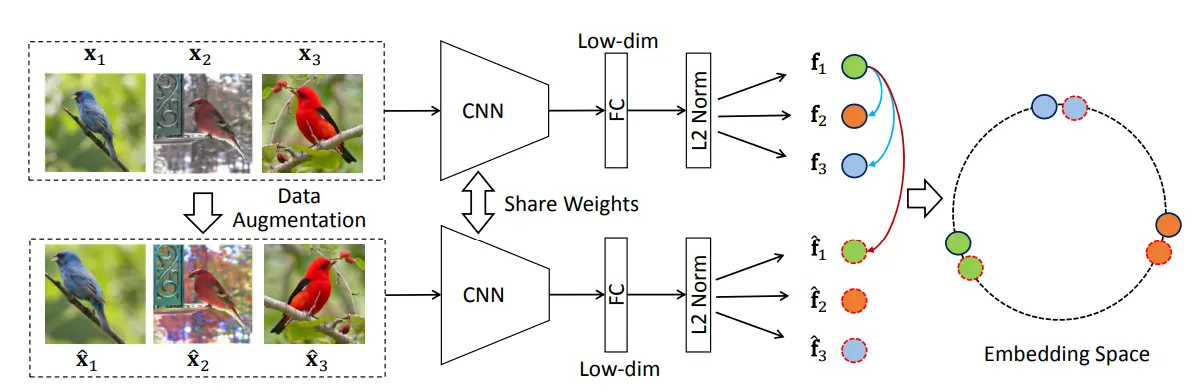
没有存储大量的负样本,训练的正负样本都来自同一个mini batch。
# 方法
在一个mini batch中,假如batch size为256,对这些图片做数据增强,之后将原图像作为正样本,其他所有的原图像与增强后的图像都作为负样本,这样一个batch中的正样本有256个,负样本有(256-1)*2个,使用一个编码器做端到端的训练。
但这篇论文的效果并不是特别好,因为在做对比学习的时候,负样本要尽可能的多
# 读论文后总结
主要思想:
通过数据增强构造正样本,通过CNN网络提取图像特征,并构造了一个负对数似然损失,通过最小化该损失令相似图像在特征空间中靠近,其他图像特征远离,并使用knn验证最后结果。
创新点:
减少了计算量,不需要使用所有的负样本,而是每一个batch中的数据自己与自己比较
如何应用自己实验:
增强---->差分、趋势项、季节项等
网络结构更换---->Transformer、一维卷积
总之就是想方法提取数据中的特征之后使用KNN等方法比较
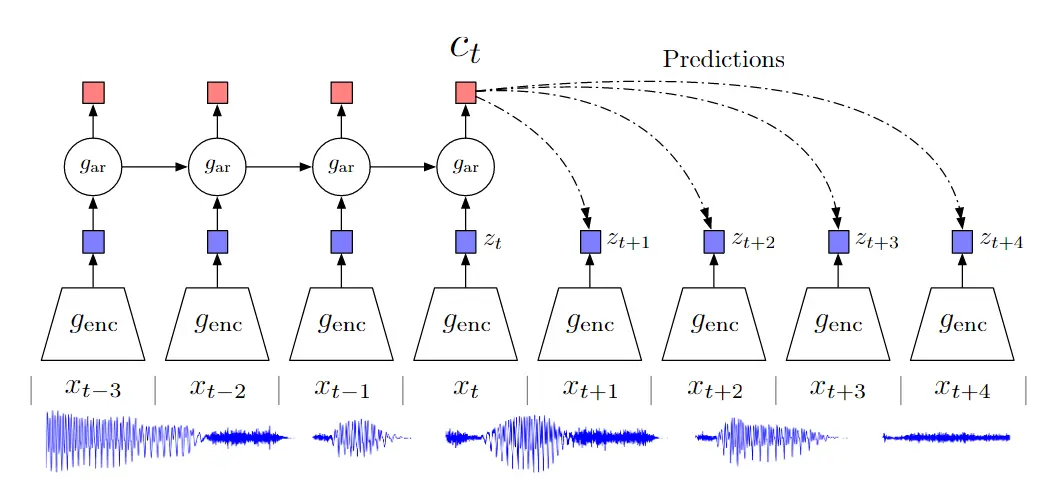
# 3. Representation Learning with Contrastive Predictive Coding(可以用于序列任务)
用预测去做对比学习
非常灵活,换成单词或图片中的patch都可以
# 4. Contrastive Multiview Coding
# 思想
一个物体的很多个视角都能作为正样本(相当于不同的观察方式:深度、分割等)
增大视角之间的互信息
如何区分正负样本:同一个图片的不同视角都可以作为正样本
局限:在处理不同视角或不同模态数据时,可能需要不同的编码器
# 读论文笔记与思考
该论文的思想是学习图像不同视角的特征表示,以同一输入的不同视角互为正样本,不同输入的不同视角为负样本,作者根据这一特点设计了多个编码器,对不同视角的图像单独进行编码,这些编码器可以共享参数或独立训练,此外,作者还设计了一个对比学习损失函数,对于每个正样本对,通过计算两个视图的特征向量之间的相似度来确定其距离,而对于每个负样本对,则通过计算相同视图中的两个随机选择的特征向量之间的相似度来确定其距离。在模型学习时,就是通过最小化正样本对之间的距离和最大化负样本对之间的距离来优化特征表示。
问题:损失函数中是否为正样本之间的距离设置权重,因为如果出现正样本之间距离稍远但负样本之间距离比较大的情况,模型是不是就忽略了正样本之间的距离问题
# 5. Momentum Contrast for Unsupervised Visual Representation Learning(MoCo)
# 贡献
将之前很多对比学习的工作都归纳成了一个字典查询的问题,提出了队列和动量编码器,从而去形成一个又大又一致的字典帮助更好的对比学习

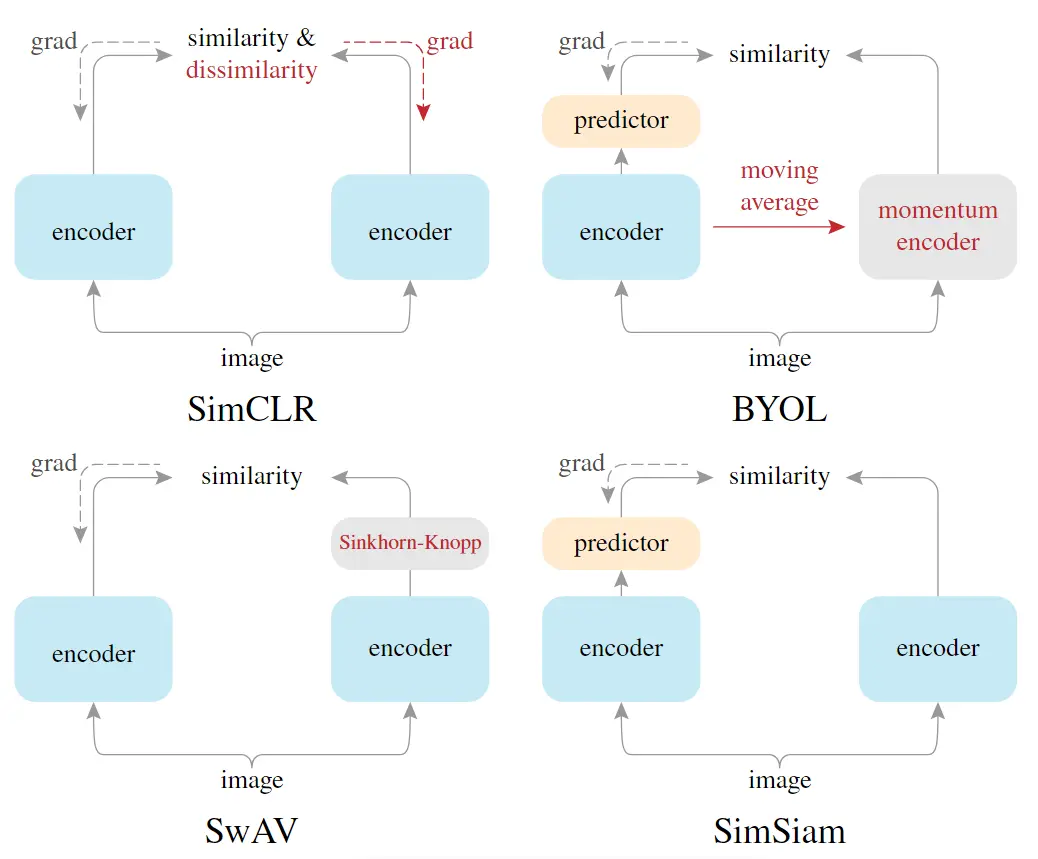
# 6. A Simple Framework for Contrastive Learning of Visual Representations(SimCLR)
# 贡献
和2论文思想差不多,但在得到特征之后加入了一个mlp层,进行了一次非线性变换,简单的结构却得到了很好的效果
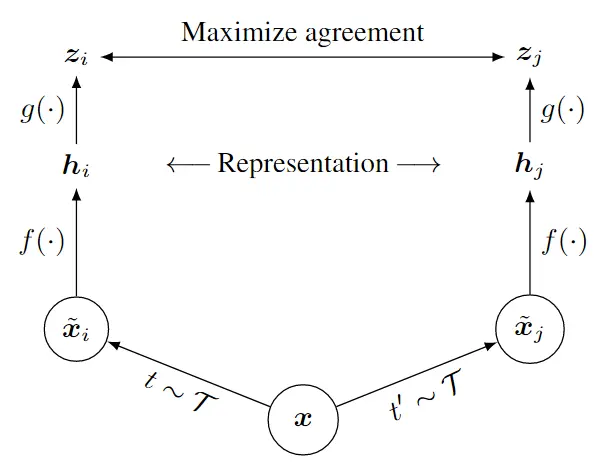
# 7. Improved Baselines with Momentum Contrastive Learning(MoCo v2)
将SimCLR的一些改进放到了MoCo上
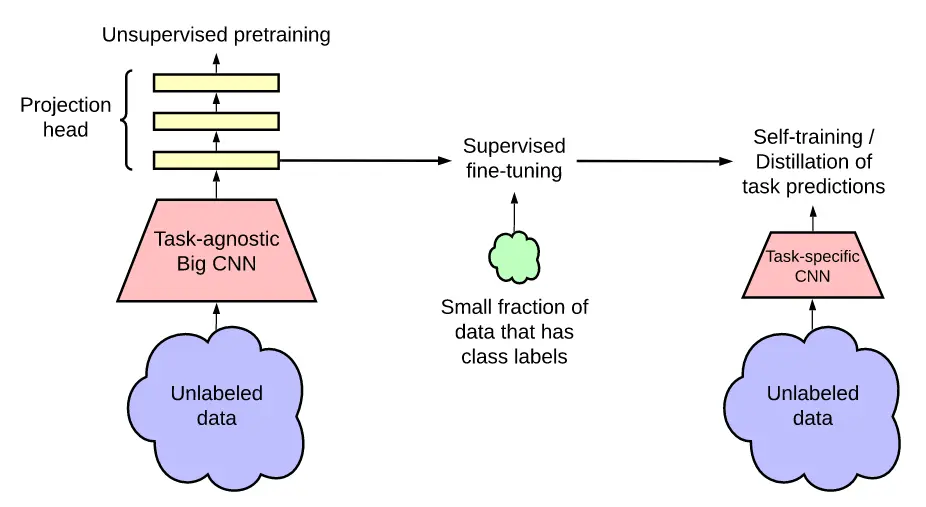
# 8. Big Self-Supervised Models are Strong Semi-Supervised Learners(SimCLR V2)
# 改进
- 使用了更大的模型
- mlp层数加深
- 也使用了动量编码器
# 9. Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
把对比学习和聚类的方法进行结合,相似的物体靠近,不相近的远离
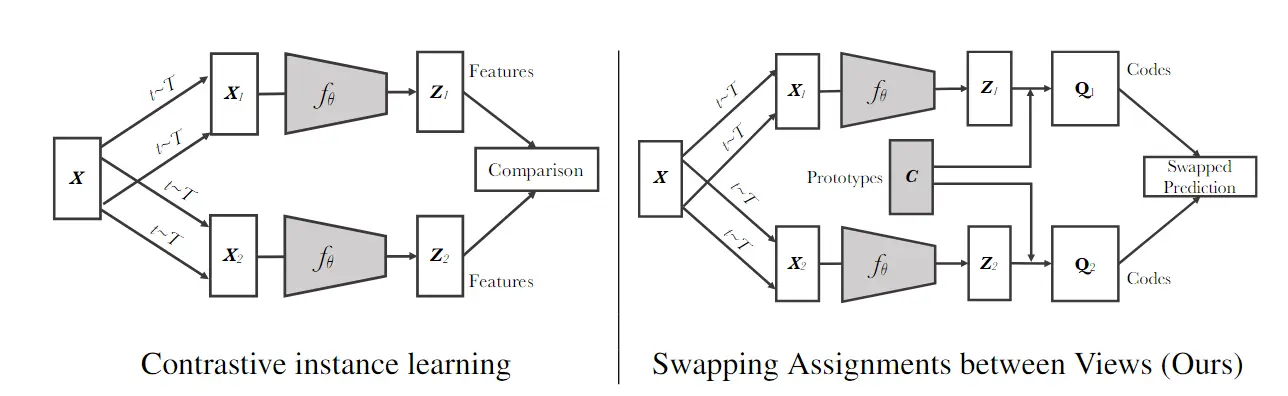
其它参考论文:deep cluster、deep cluster2
multi crop
# 10. Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
不使用负样本进行对比学习
自己预测自己
用自己一个视角的特征去预测另一个视角的特征

# 探究
# 可能原因1
BYOL不使用负样本训练不坍塌是使用了BatchNorm。解释:BatchNorm在计算的时候能够看到其它样本的部分特征,存在一定的信息泄露
正样本图片与平均图片有什么差别
# 可能原因2
模型需要比较好的初始化
可以去看 BYOL works even without batch statistics 这篇论文
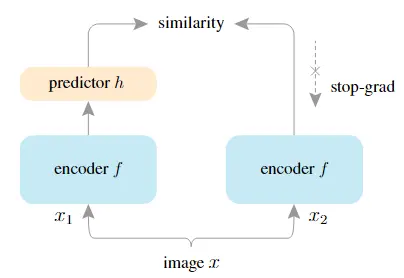
# 11. Exploring Simple Siamese Representation Learning(SimSiam)
# 特点
- 不需要负样本
- 不需要很大的batch size
- 不需要动量编码器
# 12. An Empirical Study of Training Self-Supervised Vision Transformers(MoCo V3)
# 13. Emerging Properties in Self-Supervised Vision Transformers(DINO)
# 总览