 Gated Transformer Networks for Multivariate Time Series Classification
Gated Transformer Networks for Multivariate Time Series Classification
Gated Transformer Networks for Multivariate Time Series Classification: 多元时间序列分类的门控Transformer网络
# 摘要
用于时间序列分类的深度学习模型(主要是卷积网络和LSTM)已经得到了广泛的研究,在医疗保健、金融、工业工程和物联网等不同领域得到了广泛的应用。 同时,Transformer Networks最近在各种自然语言处理和计算机视觉任务上取得了前沿性能。 在这项工作中,我们探索了带门控的电流互感器网络的一个简单扩展,称为门控变压器网络(GTN),用于多元时间序列分类问题。 通过合并Transformer的两个塔的门控,分别对通道级和步进级相关性建模,我们展示了GTN如何自然而有效地适用于多元时间序列分类任务。 我们对13个数据集进行了综合实验,并进行了完整的消融研究。 我们的结果表明,GTN能够实现与当前最先进的深度学习模型相竞争的结果。 我们还探索了GTN在时间序列建模上的自然可解释性的注意图。 我们的初步结果为变压器网络的多元时间序列分类任务提供了强有力的基线,并为今后的研究奠定了基础。
# 网络介绍
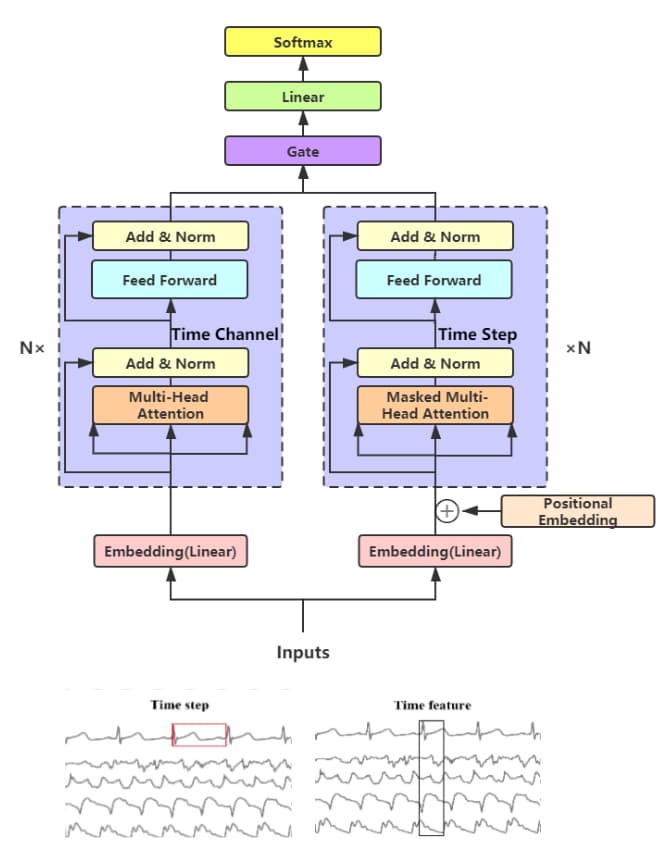
传统的Transformer网络在词上进行编码器和解码器的叠加和位置嵌入,实现序列生成和预测任务。对于多元时间序列分类, 我们有三个简单的创新来适应我们的需求:嵌入、双塔Transformer和门控。门控Transformer网络的总体结构如上图所示
# 嵌入
由于原始的Transformer是做机器翻译的,因此token需要经过Embedding层转换为向量,但时间序列本身就是连续的, 因此这里将Embedding简单地改为全连接层,代替线性投影,并添加了一个激活函数tanh。
同时,由于自注意力机制难以直接利用时间步长的顺序相关性,这里将非线性变换后的时间序列数据后加入位置编码对时间信息进行编码。
# 双塔Transformer
多元时间序列有多个通道,类似于彩色图片的RGB三通道,常见的假设是,不同通道之间存在着隐藏的相关性,之前往往是使用CNN去提取这种信息。
与其他利用原始Transformer进行时间序列分类和预测的工作不同,文章设计了一个简单的双塔框架扩展,其中每个塔中的编码器通过Attention和mask显式地捕获step-wise和channel-wise。
Step-wise Encoder:
这里类似于传统Transformer的编码器,对序列数据时间步上的每一个时间节点,计算自注意力,并堆叠残差层、正则化和前馈层。
为什么要加mask?(不懂)
Channel-wise Encoder:
类似的,该编码器不在时间步上计算自注意力,而是计算不同通道之间的自注意力,由于不同通道间的位置没有相对或绝对相关性,如果我们切换通道的顺序,将不会有任何影响,因此只在Step-wise Encoder上添加位置编码。
如何获取两种输入数据?
通过简单地转置通道和时间轴就能实现
# 门控
为了合并两个编码器的特征,一个简单的方法是连接来自两个塔的所有特征,这妥协了两者的性能。
文章提出了一个简单的门控机制来学习每个编码器的权重,在得到每个编码器的输出后,在两个编码器的非线性激活C和S输出后都有一个全连接层, 将它们级联成向量,然后经过线性投影层到h。 在softmax函数之后,计算门控权重为g1和g2,然后每个门控权重都参与到对应的编码器的输出,并打包为最终的特征向量
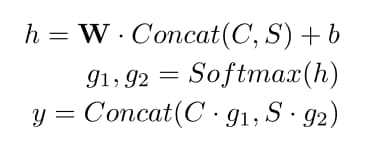
问题? 输出是一个特征向量,如何评价损失,又如何进行分类?
有可能Gate里面包含着一个线性层和softmax,代码里的gate是通过一个线性层把维度变为2,再经过一个softmax输出得到权重,与两个编码器的输出结合作用后在通过一个线性层得到结果,输出维度是分类的类别数