 SwingTransformer
SwingTransformer
# Transformer与Vision Transformer对比
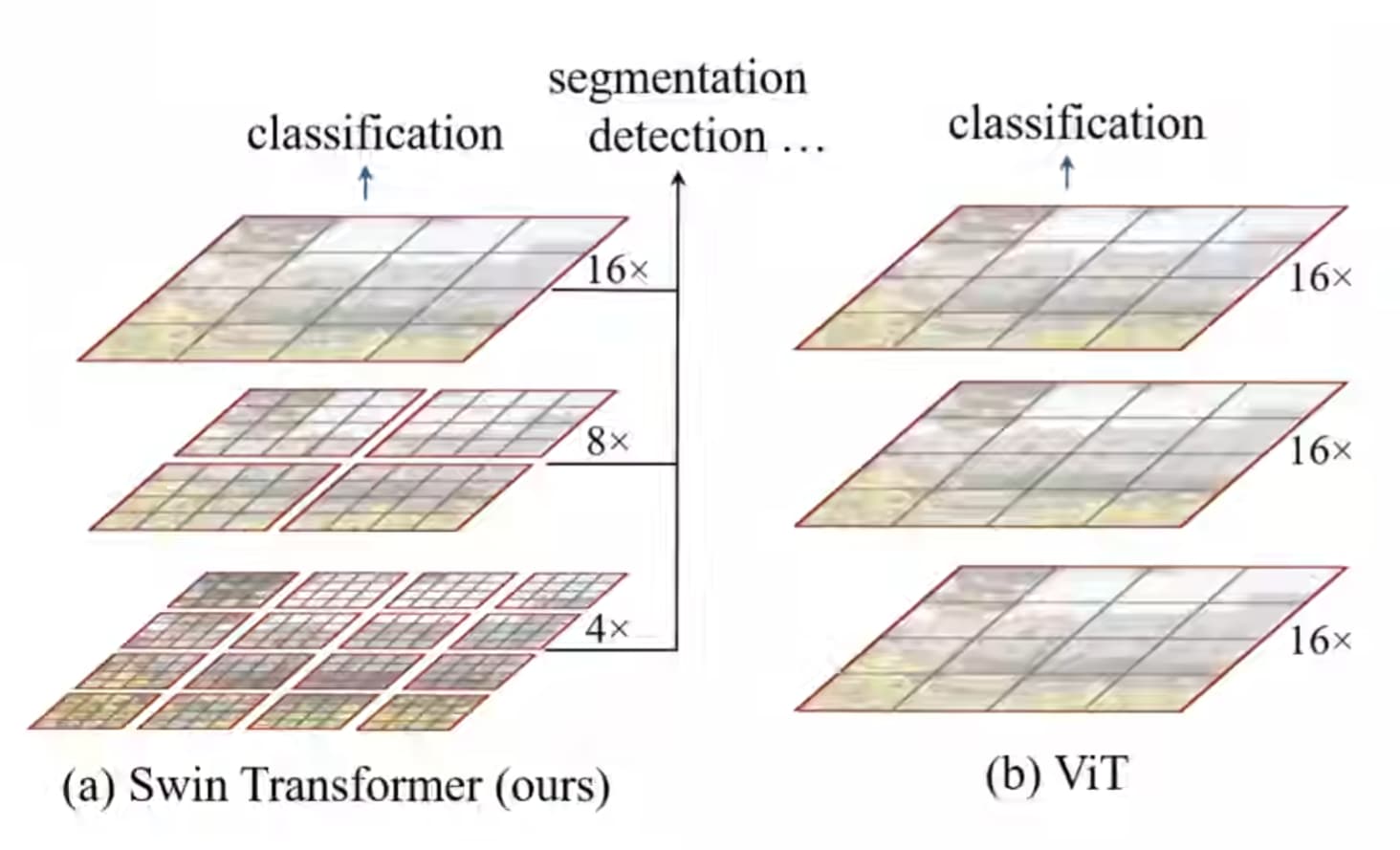
不同:
- Swin Transformer构建的feature map是具有层次性的,网络越深下采样倍率越大
- 红框为窗口。Swin Transformer的窗口是分开的,VIT是连起来的,这样做能够大大减低运算量
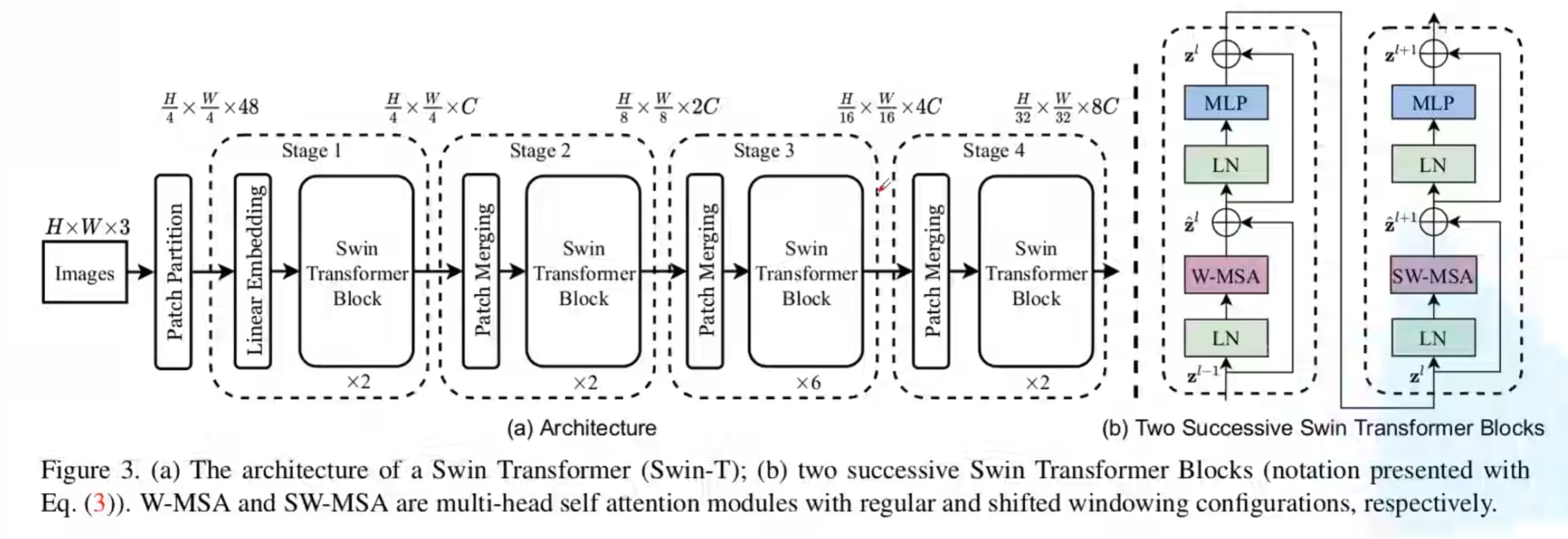
# 整体框架图
Patch Partition:
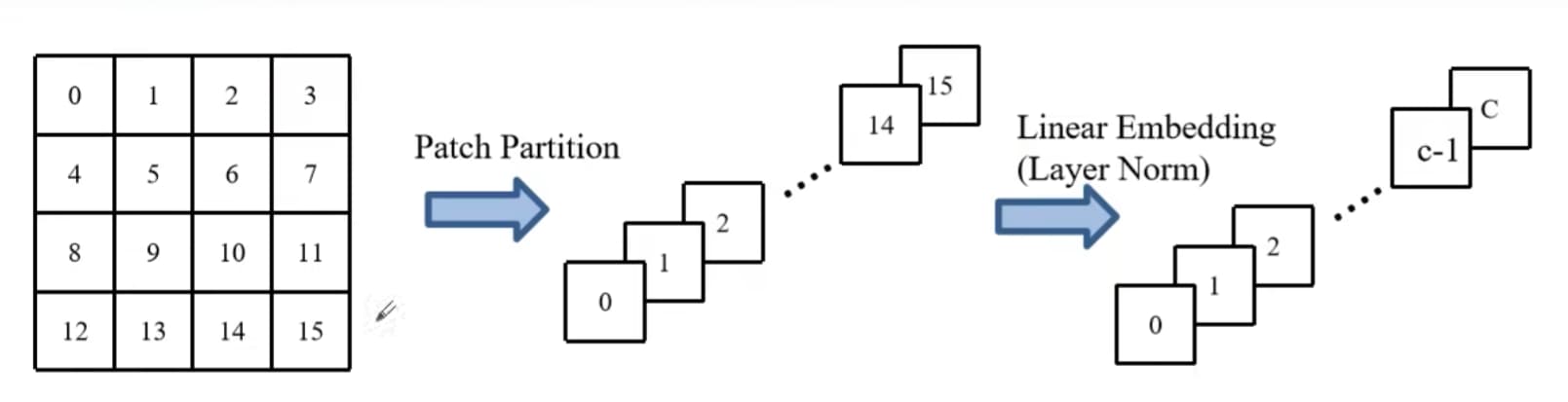
将图片的每一个窗口,将它的patch在channel方向进行展平
整体框架图中经过Patch Partition后的48就是RGB三通道数展平后的16块即316得到的
之后,通过Linear Embeding层对每个像素的channel数据做线性变换,由48变成C
# Patch Merging
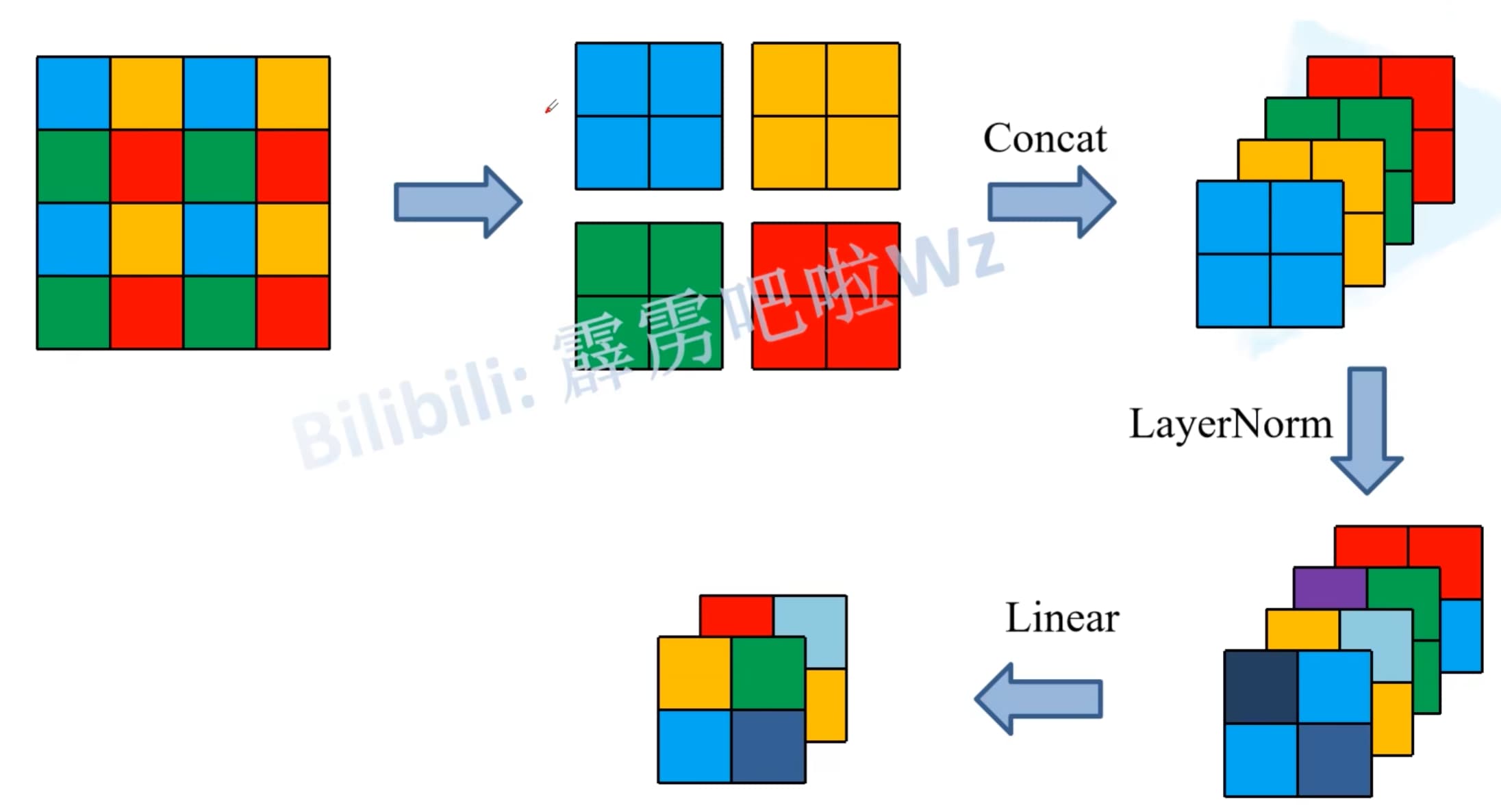
每个窗口中的patch被分为四类,将相同位置的patch放置在一起,在通道方向进行连接,并对每一个通道分别进行LayerNorm,最后经过一个线性层将通道数减半,最后整体的效果就是feature map的通道数翻倍,高和宽减半
# W-MSA
全称:窗口-多头注意力
目的:减少计算量
缺点:窗口之间无法进行信息交互
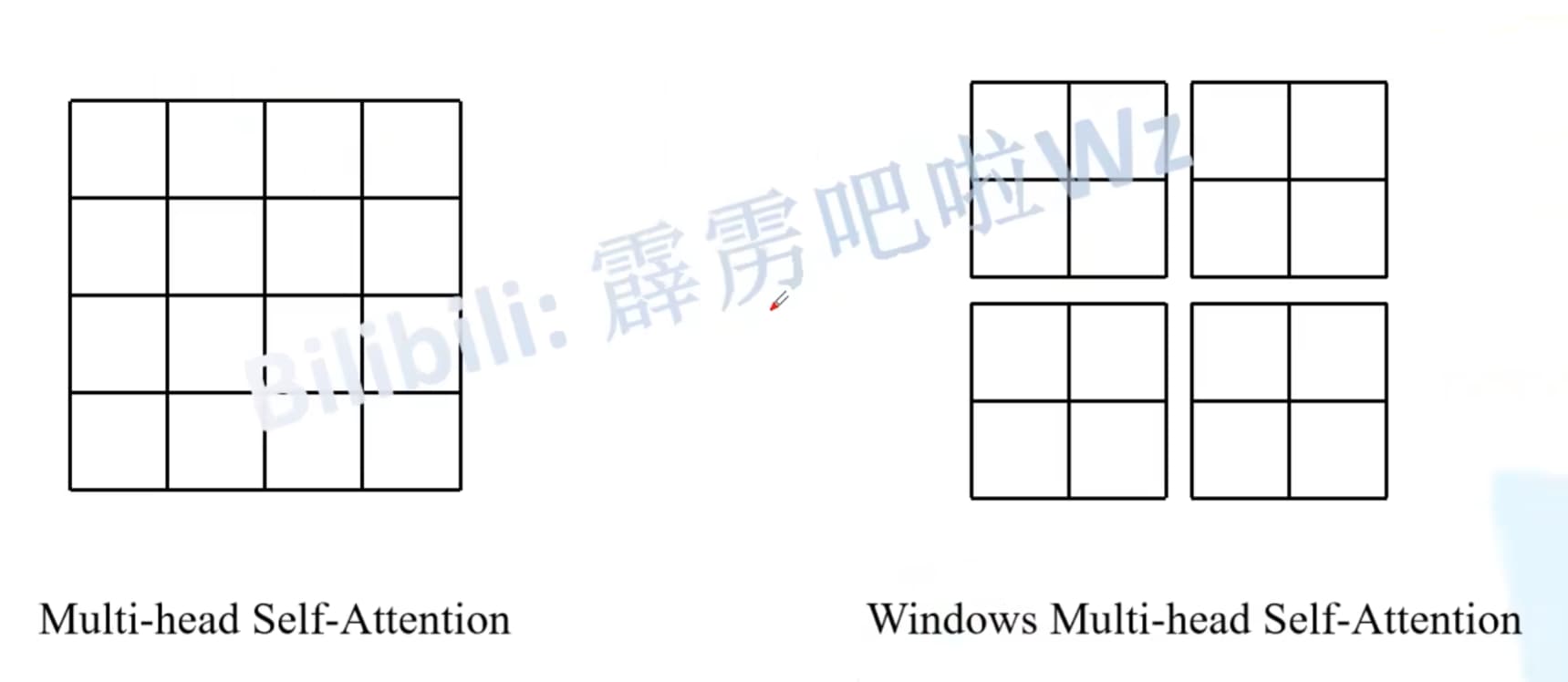
原MSA:图片上的每一个像素对其他所有像素做self attention
W-MSA:每个窗口内部做self attention
节省的计算量:

# Shifted Window
目的:实现不同window之间的信息交互,之前情况中窗口与窗口之间是没有通讯的
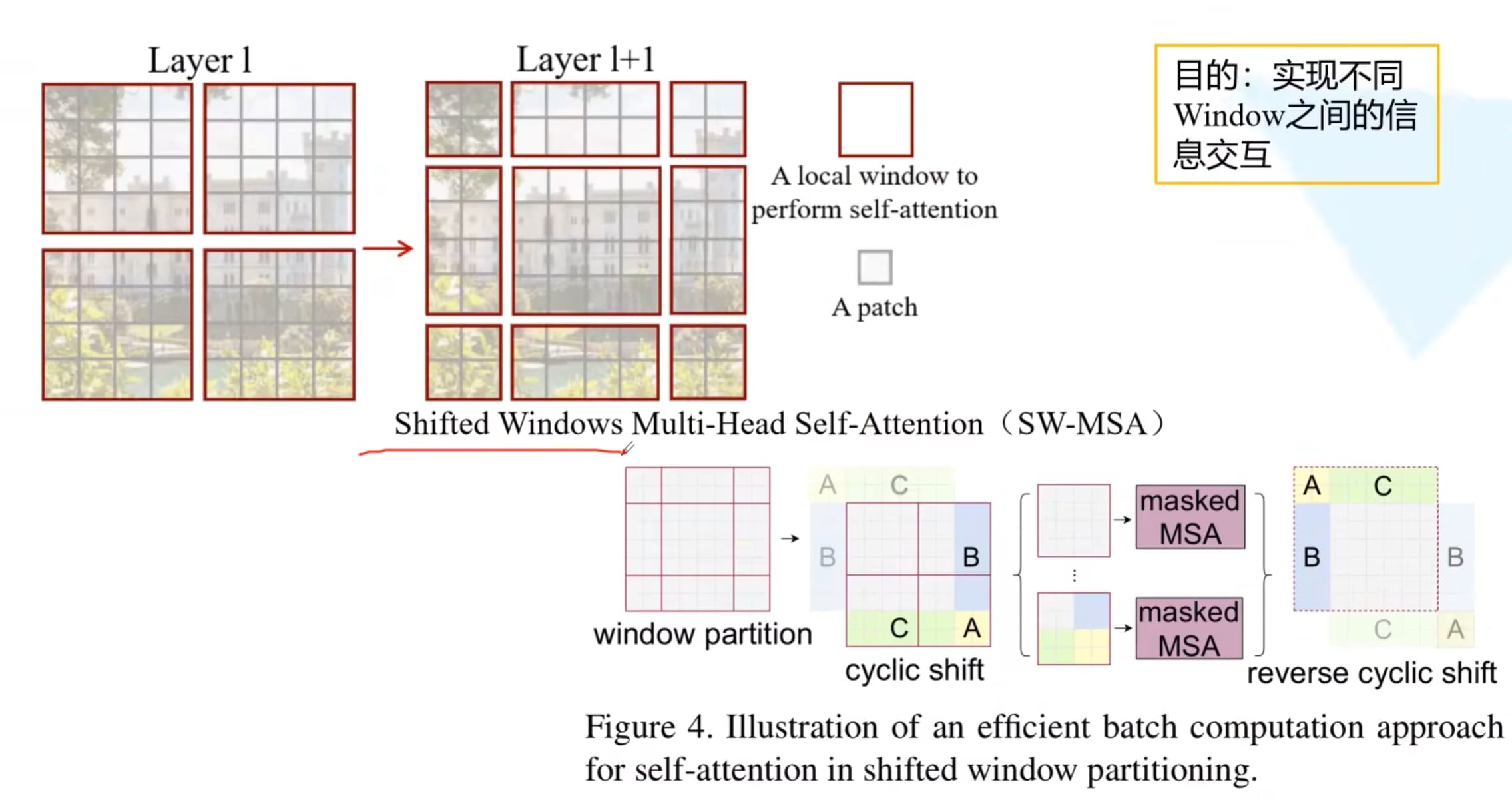
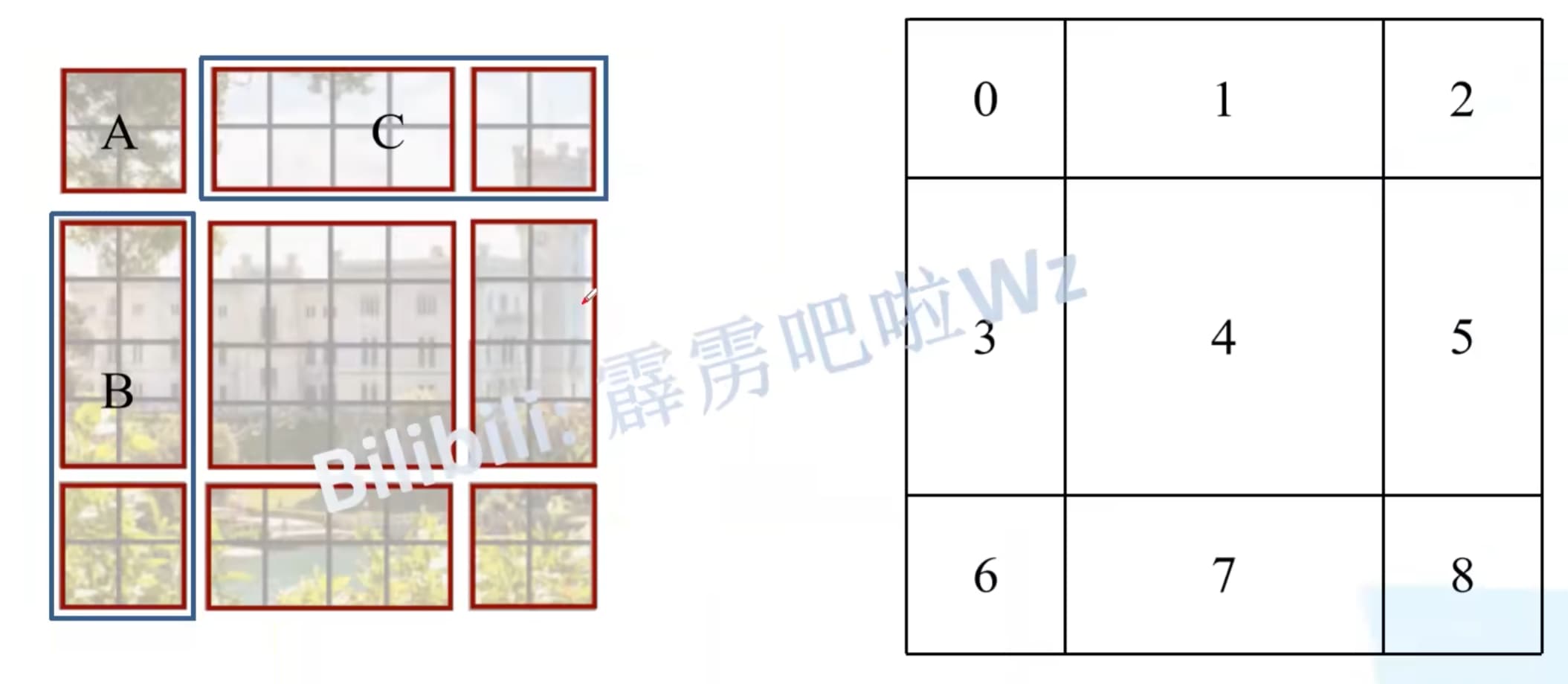
变换之后的窗口能够计算不同之前不同窗口之间的自注意力,但如果直接进行计算的话,将需要计算9个窗口的自注意力,因此作者采用了另外一种方法
原分割情况:
窗口转换之后结果:
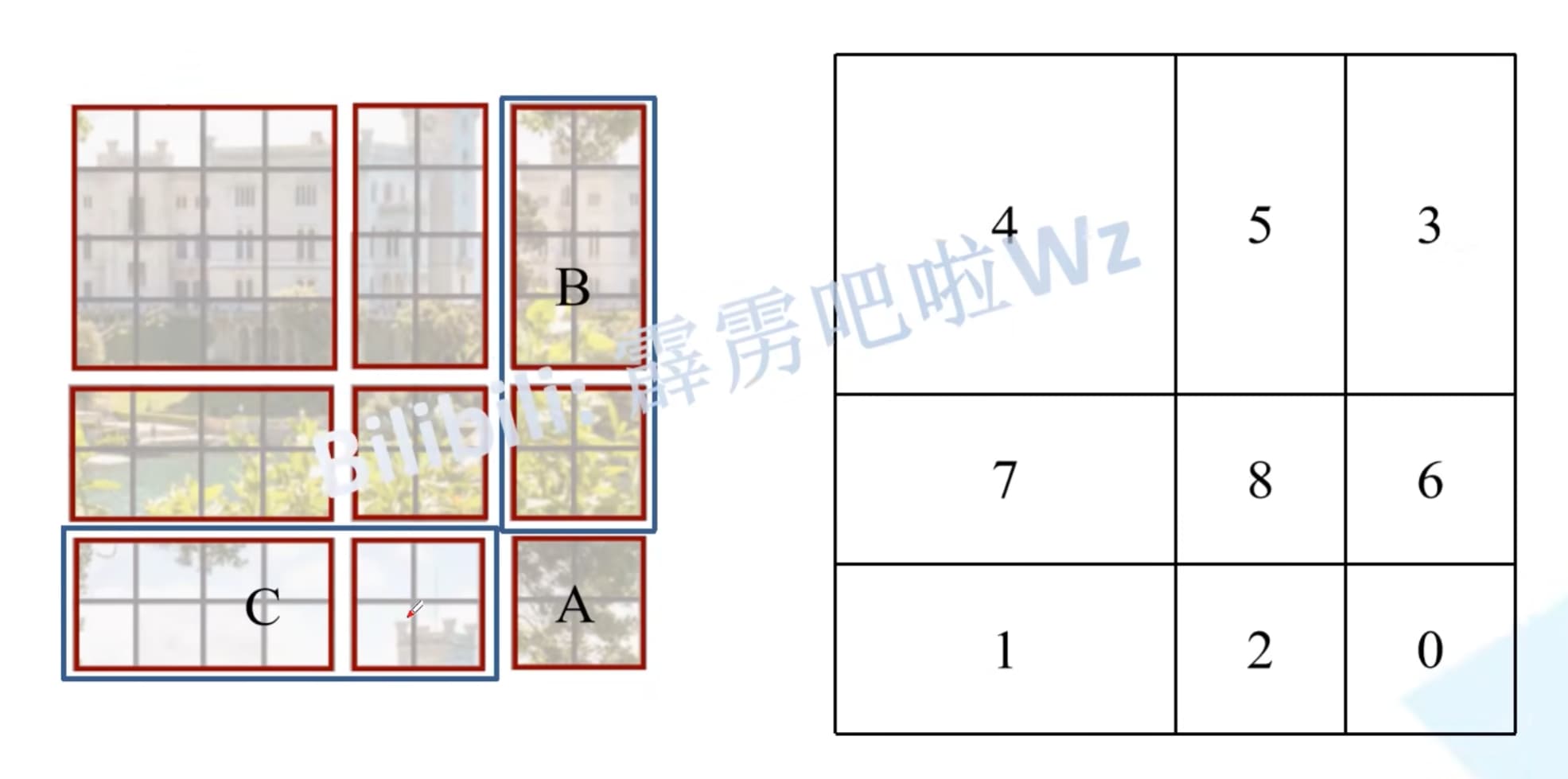
具体计算图(以5、3区域为例):
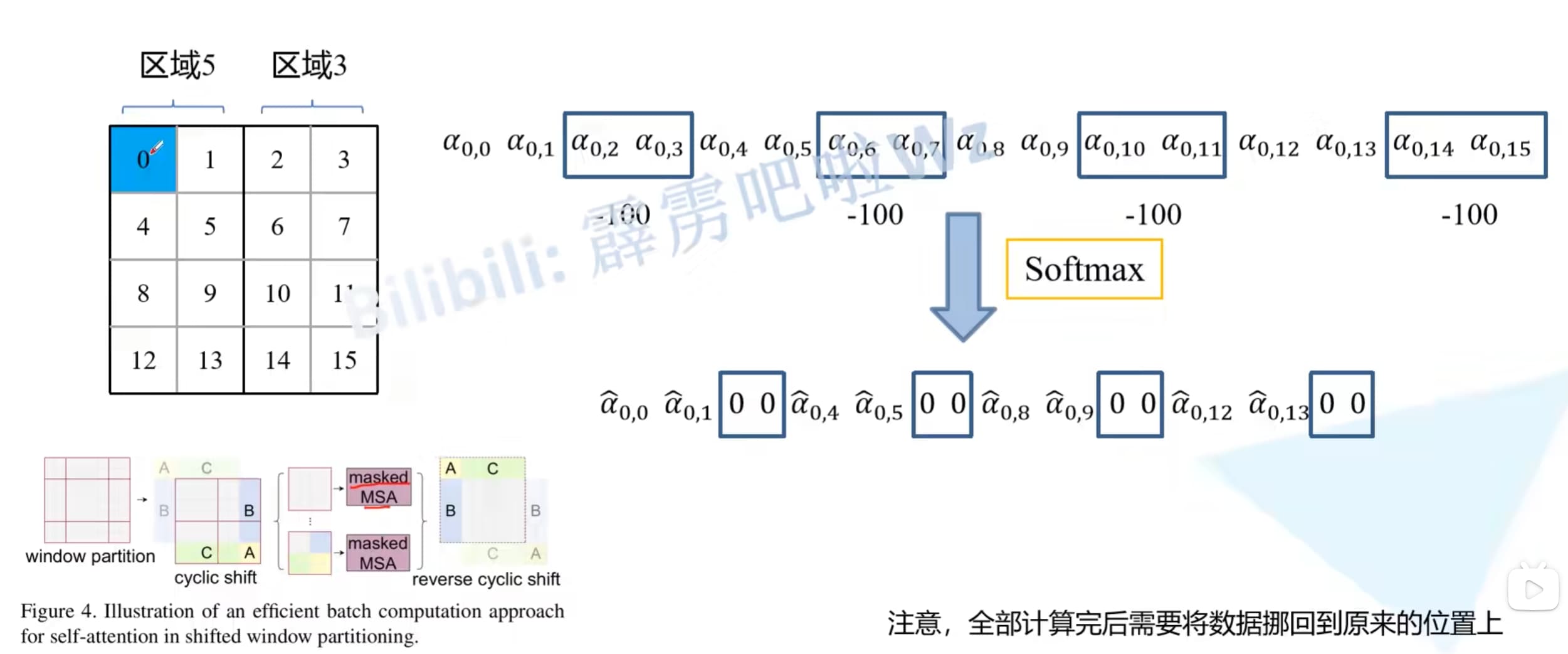
计算注意力的时候依旧是对一整块区域计算注意力,但区域5和区域3之间交叉的地方需要抛弃,这里采用的方法是在给定位置一个比较小的数,这样做softmax就会变成0,也就消失了
# 参考资料
编辑 (opens new window)
上次更新: 2024/05/30, 07:49:34