 CLIP改进工作
CLIP改进工作
# CLIP【Learning transferable Visual Models From Natural Language Supervision】
# 简单介绍
通过图像文本对之间进行对比学习预训练网络,将预训练网络迁移到其他数据集做Zero-Shot的分类任务,有非常好的泛化性能与多模态能力
使用了大量的图像文本对(亿级)
# 网络模型
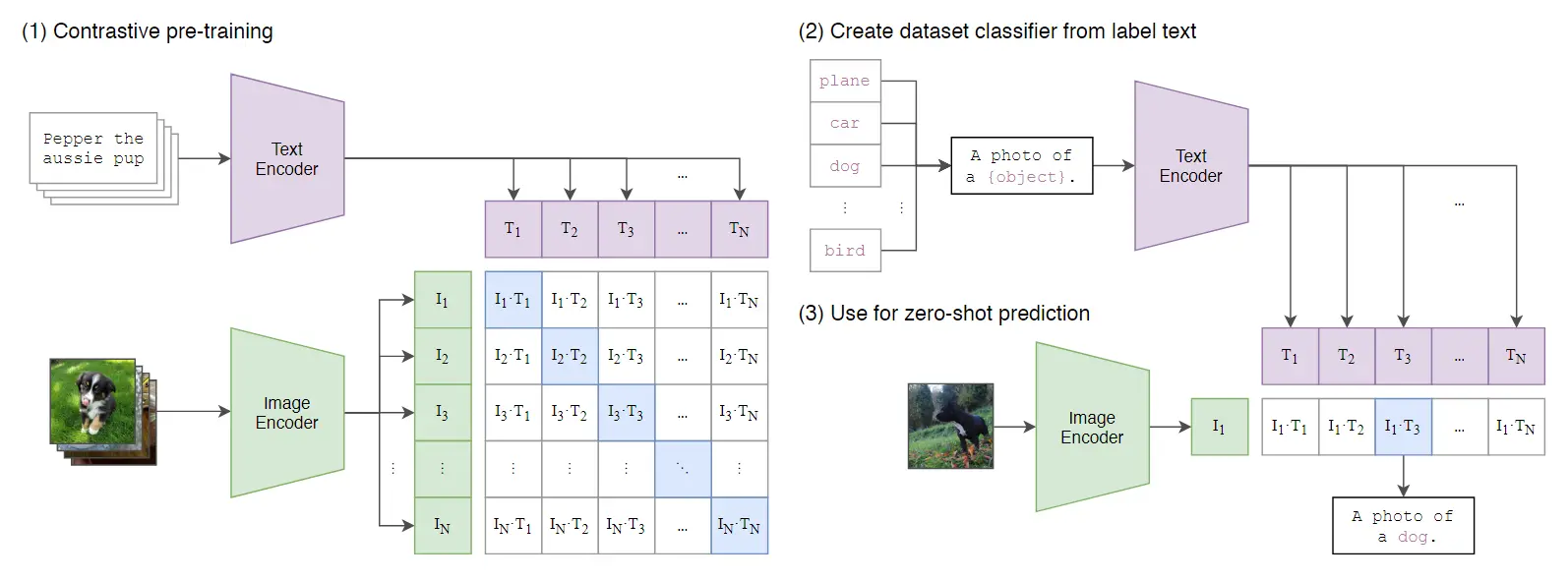
- 首先根据图像文本对计算相似度,以此计算对比损失预训练模型
- 迁移到其他数据集上:假如说1000类的ImageNet,使用一个文本prompt将类的文本填入{ }中,过文本编码器得到文本特征,将图像过图像编码器得到图像特征,计算相似度,之后过softmax将最大的作为预测类别
# Lseg【Language-Driven Semantic Segmentation】ICLR 2022
# 简单介绍
将CLIP思想用于语义分割的一篇工作,没有用到对比学习,训练过程是有监督的训练
# 实际效果
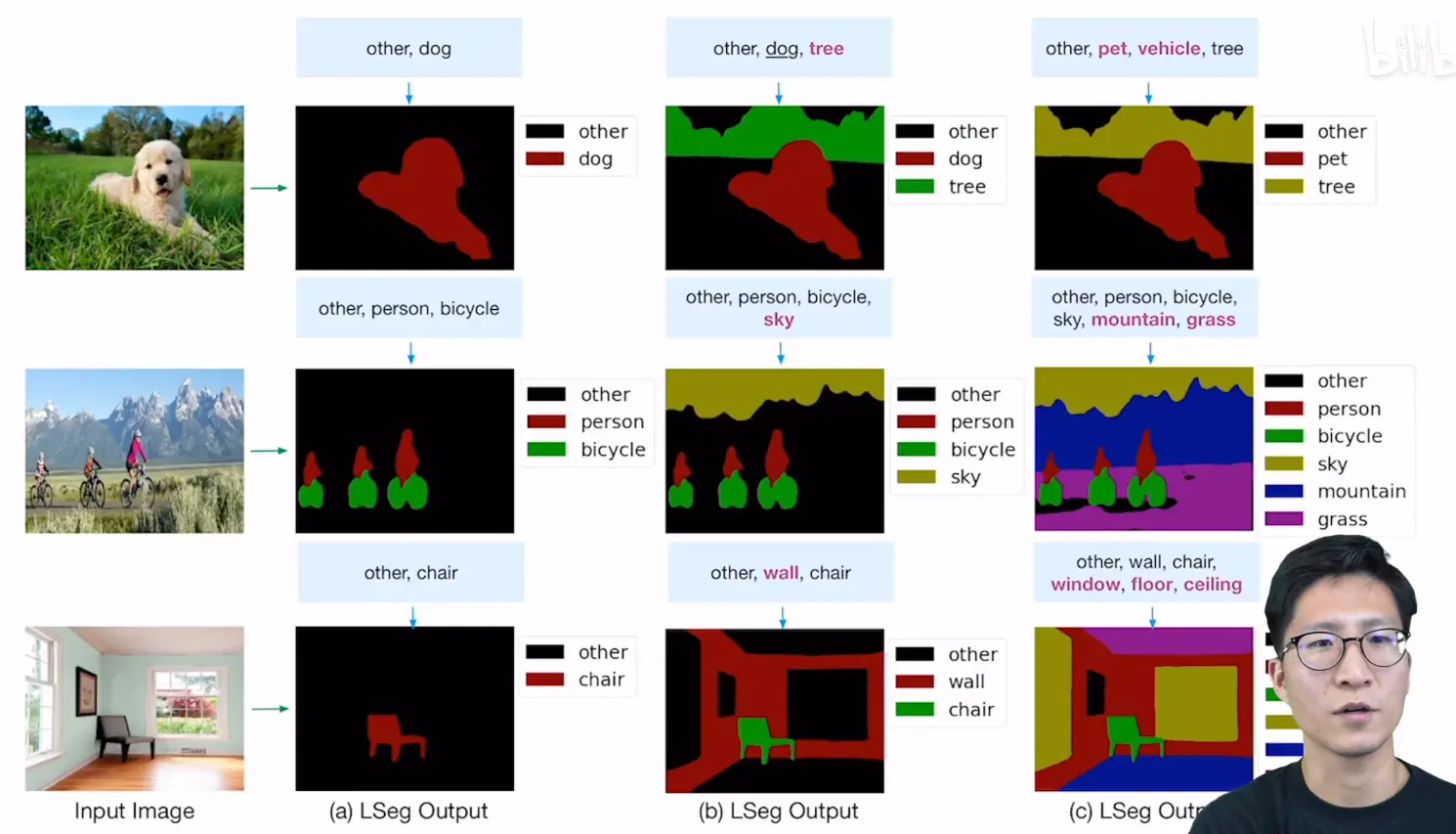
# 网络架构
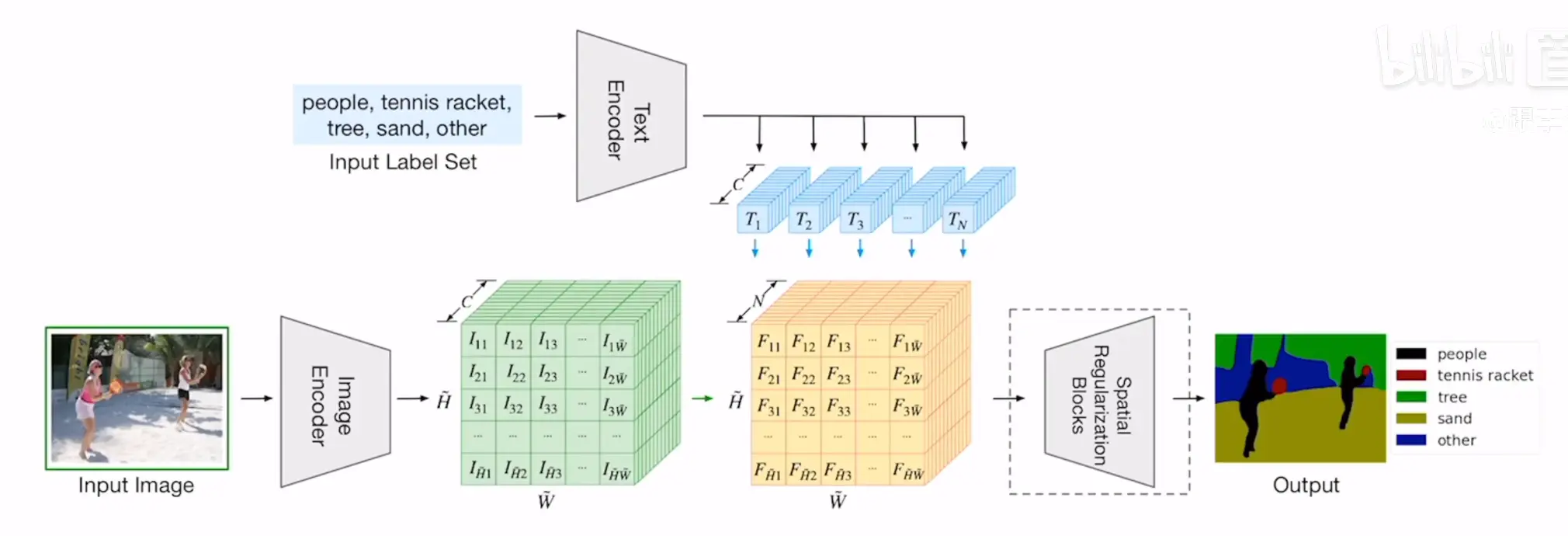
- 给定一张图片与一组文本标签,建立图像与这组文本信息的对应关系
- 文本特征与图像特征相乘,通道从C变为N
- 先降维再升维
- 最后是有ground truch mask的,计算的损失就是在这个标签上计算的
# 评价
思想很简单,只是将文本特征与图像特征乘了一下,这使得后面在使用这一模型的时候,可以使用本文作为prompt来分割图像
# Group ViT【Group ViT: Semantic Segmentation Emerges from Text Supervision】CVPR 2022
# 简单介绍
在语义分割中引入了Grouping Block,能够对图像中的像素点进行分组,解决了分割问题难以与一组文本计算对比损失的问题
# 模型介绍
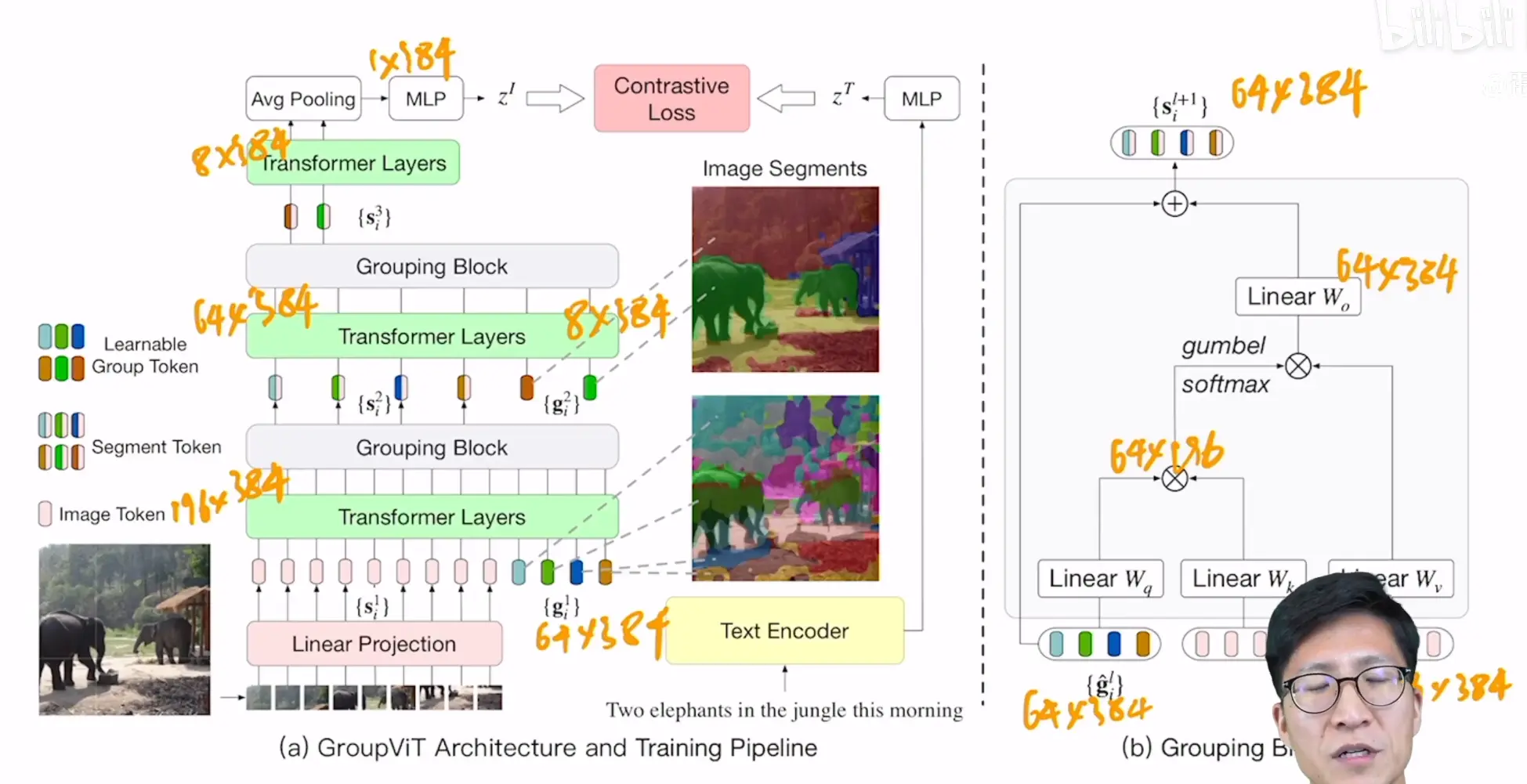
- 网络结构是ViT,在几个Transformer层中加入了两个Grouping Block层
- 第一个Grouping Block作用前先在前一个Transformer层上加入64个与特征一样大的token,可以理解为聚类中心
- 经Transformer层互相关注之后,在Grouping Block内部,经过几次矩阵乘法将特征的数量变为与之前加入的token数量,即64,这个过程可以看做是一个细分类
- 在Grouping Block内部,用到了gumbel softmax使这一过程变为可学习的,因为其中有一项矩阵乘法没有任何参数,无法学习
- 第二个Grouping Block与第一个中间隔了几层Transformer层,第二个与第一个计算差不多,不过减少了token的数量,以实现更宽泛的分类
- 最后将特征平均池化之后与文本特征计算对比损失
- 之后就与CLIP一样
模型使用过程如下:
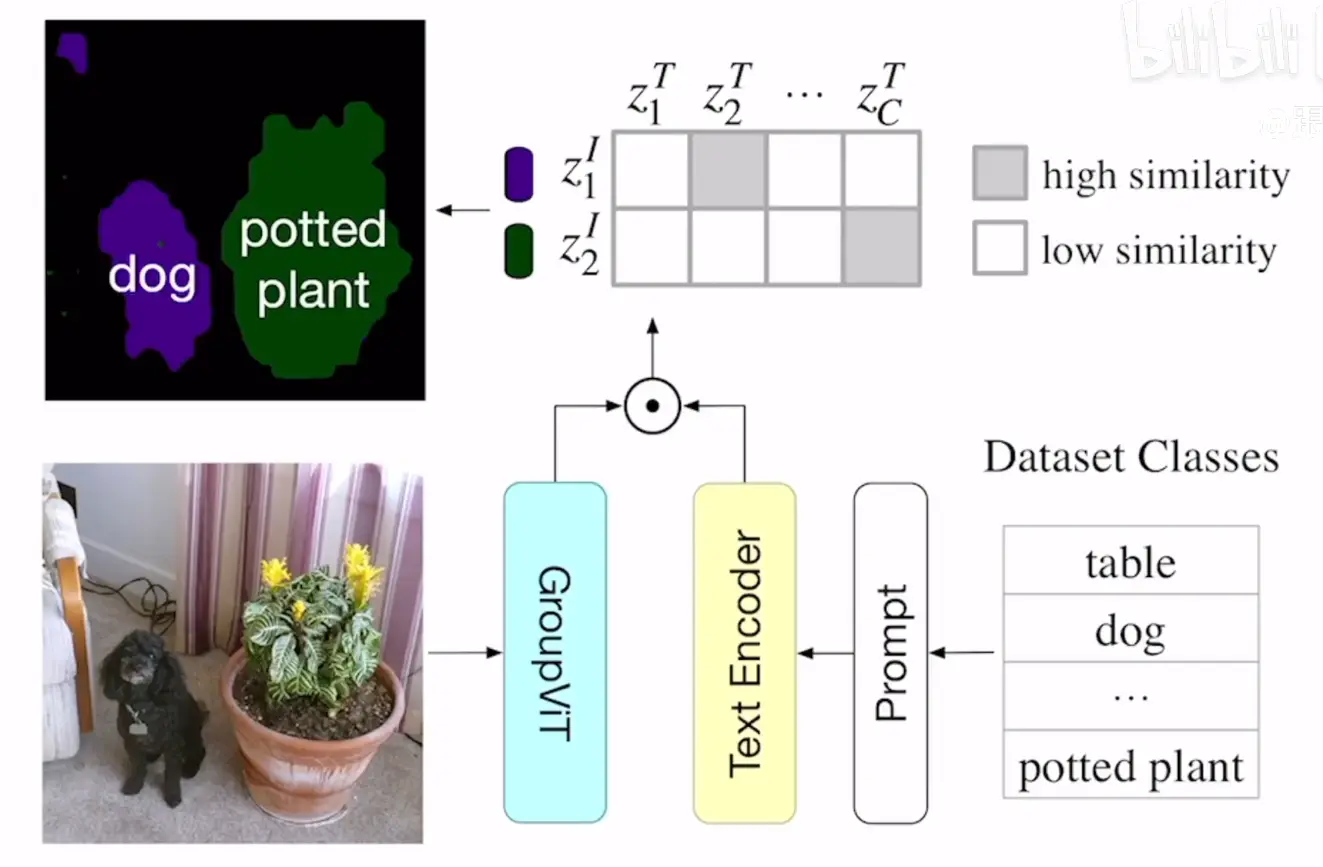
# 可视化
作者这里做了一个实验,将网络中途产生的特征单独拿出来进行分割,可以看到,第一个Grouping Block产生的特征关注的都是小物体,因为这里加入的token数量为64,比较多,而第二个Grouping Block就关注的是一些大物体了,因为这里的token数量为8

# ViLD【OPEN-VOCABULARY OBJECT DETECTION VIA VISION AND LANGUAGE KNOWLEDGE DISTILLATION】ICLR 2022
# 简单介绍
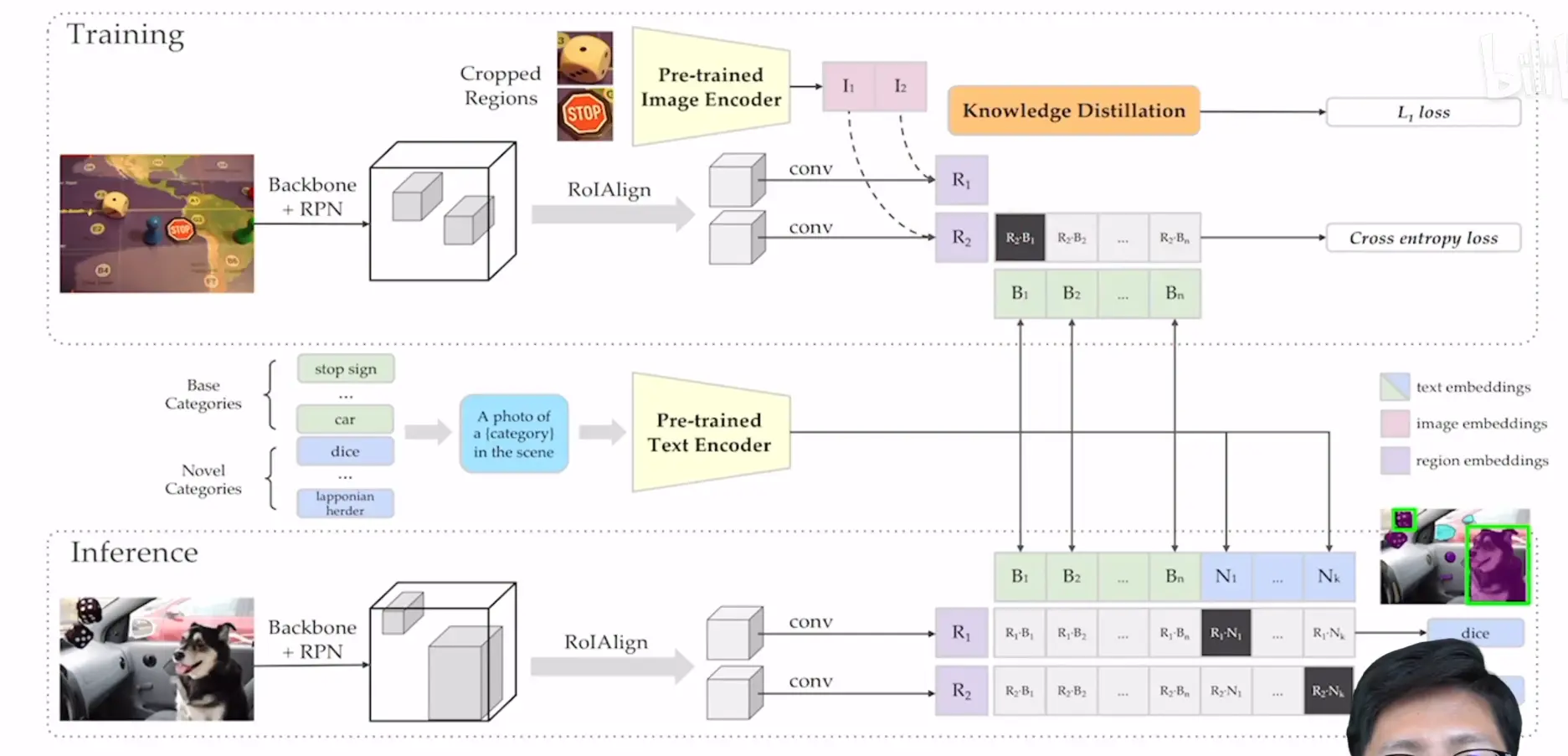
这是一个做目标检测的网络,动机是能够检测到任意新的物品类别,在已有数据集的基础上去,训练过程为有监督的
# 网络模型
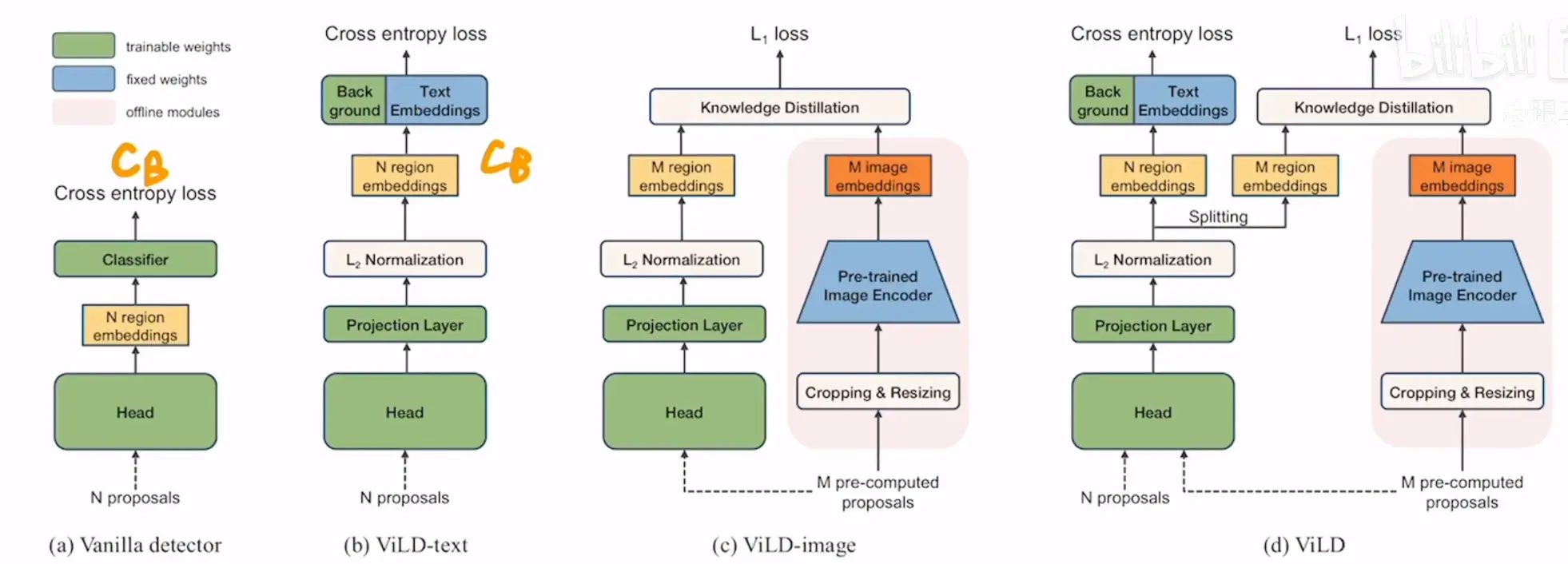
- a为baseline,就是一个maskRCNN
- 绿色的组件为可训练的,蓝色的表示不可训练,权重锁死的
- b前面一部分就是正常的提取图像特征,back ground为背景类,与文本特征一起与图像特征计算相似度,之后计算损失
- c为知识蒸馏的过程,这是为了让我们要训练网络的特征与预训练网络(CLIP)提取的特征尽可能的一致,这可以大大利用CLIP中的文本辨别力,这里的M pre-computed proposals是预先处理好的,为了减少计算量
- d就是ViLD的整体架构
更形象化的流程图:
# GLIP【Grounder Language-Image Pre-training】
# 简单介绍
通过Vision Grounding来使用图像文本对训练模型
将检测与Grounding结合起来做模型的训练,分类损失与定位损失结合
有监督学习
# 网络架构
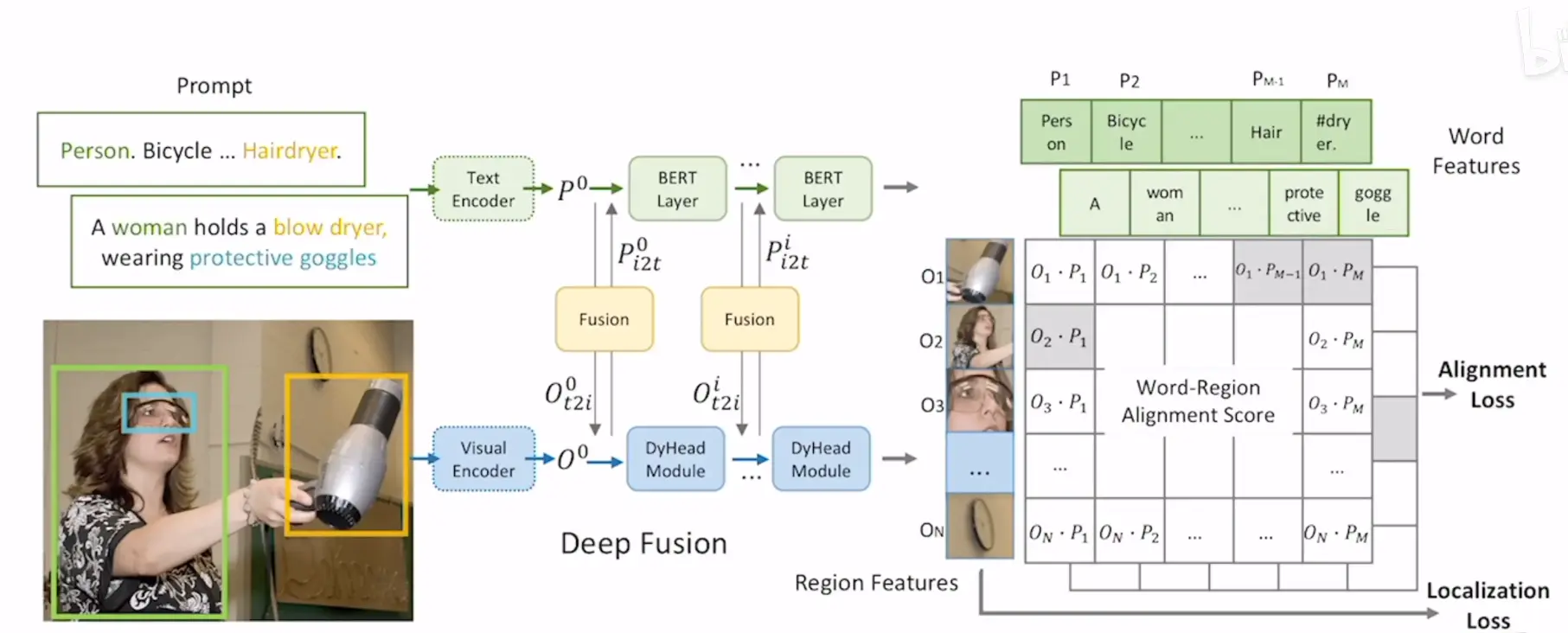
- 根据bunding box拆分图像,利用图像编码器编码图像特征,利用文本编码器编码文本prompt的特征
- 得到特征之后多过了几层网络用于特征融合,以达到更好地效果
- Alignment Loss就是图像文本对的相似损失,Localization Loss就是目标检测中的定位损失
# CLIPasso:Semantically-Aware Object Sketching
保持语义信息的简笔素描

抽象非常重要
网络前面几层的特征有更具体的空间信息(位置、几何形状、朝向等)
编辑 (opens new window)
上次更新: 2024/05/30, 07:49:34