 A survey on semi-supervised learning
A survey on semi-supervised learning
# 摘要
半监督学习是机器学习的一个分支,涉及使用标记和未标记的数据来执行某些学习任务。从概念上讲,位于监督学习和无监督学习之间,它允许利用许多用例中可用的大量未标记数据,并结合通常较小的标记数据集。近年来,该领域的研究遵循了机器学习中观察到的总体趋势,主要集中在基于神经网络的模型和生成学习上。关于该主题的文献也在体积和范围内扩展,现在涵盖了广泛的理论、算法和应用。然而,目前还没有最近的调查来收集和组织这些知识,阻碍了研究人员和工程师喜欢利用它的能力。填补这一空白,我们对半监督学习方法进行了最新的概述,涵盖了早期的工作以及最近的进展。我们主要关注半监督分类,其中发生了绝大多数半监督学习研究。我们的调查旨在为该领域的研究人员和从业者提供新的研究人员和从业者,并对过去二十年开发的主要方法和算法有坚实的理解,重点是最突出的和目前相关的工作。此外,我们提出了一种新的半监督分类算法分类法,揭示了将未标记数据纳入训练过程的不同概念和方法方法方法。最后,我们展示了大多数半监督学习算法的基本假设如何彼此紧密相连,以及它们如何与众所周知的半监督聚类假设相关。
# 引言与背景
# 半监督的直观作用
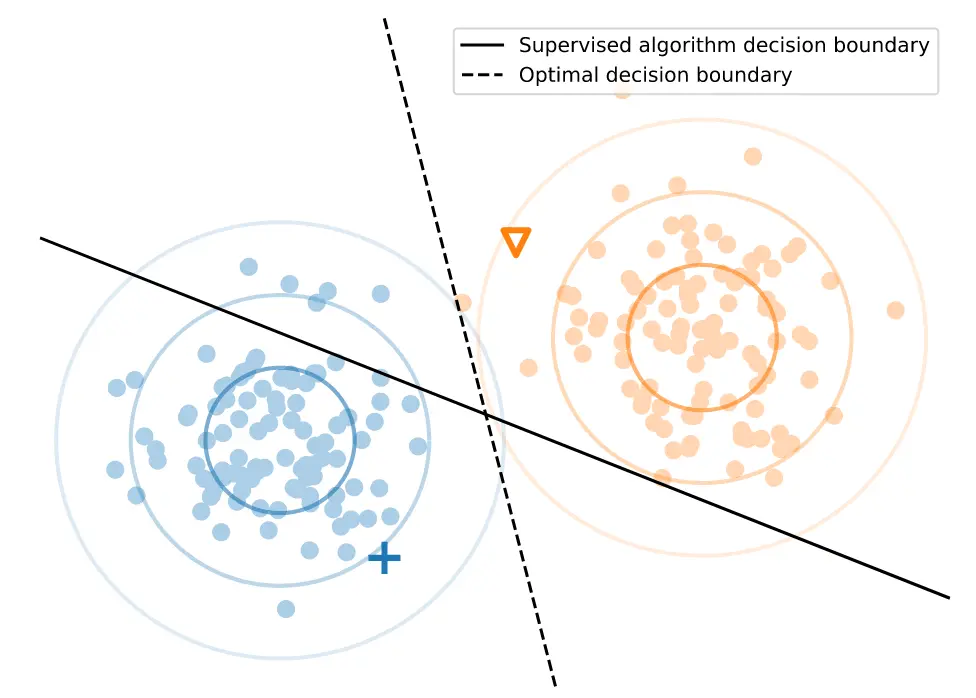
对于下图,如果标记数据仅为高亮显示的,那么大部分监督算法都会吧实线作为分类边界,但实际最优的分类边界应为虚线,那么如果使用半监督学习对未标注数据进行集群推断的话,可以帮助我们推断最优的决策边界。
# 半监督学习的假设基础
平滑度假设(Smoothness assumption):如果两个样本 x 和 x' 在输入空间中接近,它们的标签 y 和 y' 应该相同
低密度假设(Low-density assumption):决策边界不应通过输入空间中的高密度区域
流行假设(Manifold assumption):同一低维流形上的数据点应该具有相同的标签

# 半监督学习方法的分类
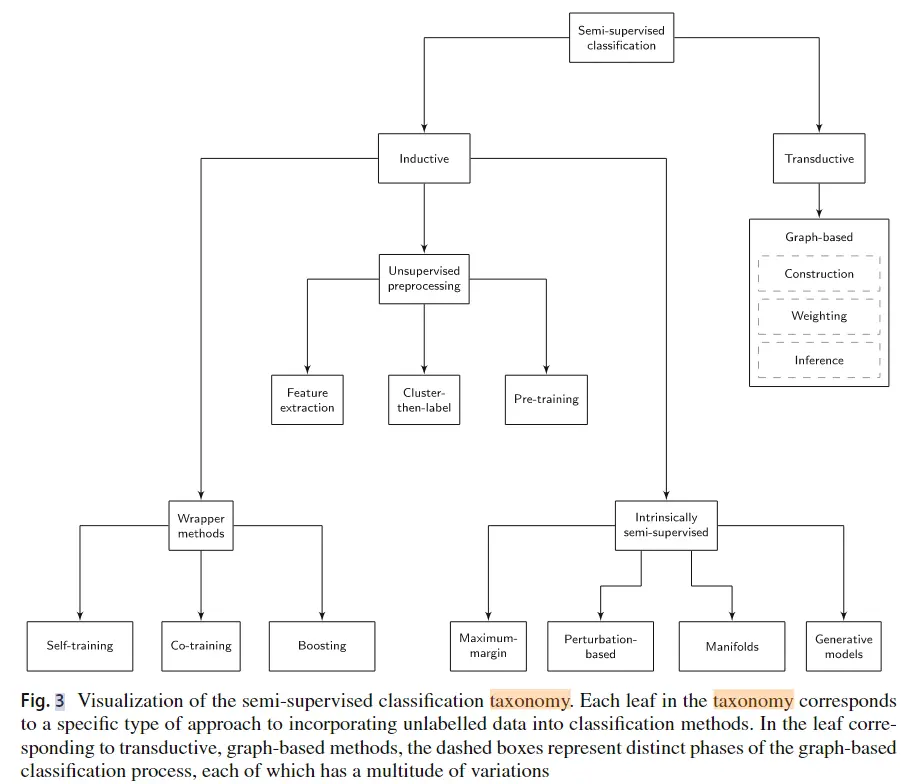
分类结果如图所示。在最高层,它区分了归纳(Inductive)方法和转导(Transductive)方法,从而产生不同的优化过程:前者试图找到分类模型,而后者只关注为给定的未标记数据点获取标签预测。在第二层,它考虑了半监督学习方法包含未标记数据的方式。这种区别产生了三类不同的归纳方法,每一种归纳方法都以不同的方式与监督分类器相关。
其中,归纳方法通过未标记数据中隐藏的信息来直接优化模型,而转导方法从未标记数据中生成预测标签扩充标签数据。
# Inductive methods(归纳方法)
归纳方法旨在构建一个分类器,该分类器可以为输入空间中的任何对象生成预测。在训练这个分类器时可以使用未标记的数据,但是一旦训练完成,对多个新的、以前未见过的示例的预测是相互独立的。这对应于监督学习方法中的目标:在训练阶段构建模型,然后可用于预测新数据点的标签。
# Wrapper methods(包装器方法、伪标签方法)
将现有监督算法扩展到半监督的一个简单方法是首先在标记数据上训练分类器,然后使用所得分类器的预测来生成额外的标记数据。然后,除了现有的标记数据之外,分类器还可以在此伪标记数据上进行训练。这种方法被称为包装器方法:未标记的数据由包装器生成伪标记,而全监督学习算法不知道原始标记和伪标记数据之间的区别,构建了最终的归纳分类器。这揭示了包装器方法的一个关键属性:它们中的大多数可以应用于任何给定的监督基础学习器,允许以直接方式引入未标记的数据。
该方法的过程通常由训练和伪标记的两个交替步骤组成。在训练阶段,一个或多个监督分类器在标记数据上进行训练,这些数据可能来自先前迭代的伪标记数据。在伪标签步骤中,生成的分类器用于推断先前未标记对象的标签;学习者对其预测最有信心的数据点被伪标记以用于下一次迭代。
优势:可以几乎与任何有监督的模型一起使用。
# Self-training(自训练)
定义:它们由单个监督分类器组成,该分类器在算法的先前迭代中对已伪标记的标记数据和数据进行训练。
在自我训练过程开始时,监督分类器仅在标记数据上进行训练。生成的分类器用于获得未标记数据的预测。然后,将这些预测的最有信心添加到标记数据集中,并在原始标记数据和新获得的伪标记数据上重新训练监督分类器。此过程通常会迭代,直到不再保留未标记的数据。
生成伪标签时非常重要的一点是置信度的确定,置信度估计的质量直接影响算法性能。
# Co-training(协同训练)
协同训练是自训练从一个监督分类器到多个监督分类器的扩展。在协同训练中,在标记数据上迭代训练两个或多个监督分类器,在每次迭代中向其他监督分类器的标记数据集添加最自信的预测。为了共同训练取得成功,重要的是基础学习者在他们的预测中没有太强的相关性。如果它们是,它们有可能为彼此提供有用的信息是有限的。
为了促进分类器的多样性,早期的协同训练方法主要依赖于数据的多个不同视图的存在,这通常对应于特征集的不同子集。例如,在处理视频数据时,数据可以自然地分解为视觉和音频数据。这种协同训练方法属于更广泛的多视图学习方法,其中包括广泛的监督学习算法。
多视图协同训练的主要假设:
- 每个单独的特征子集应该足以对给定数据集进行良好的预测(如果两个特征子集之一不足以形成良好的预测,则使用该集合的分类器永远不能对组合方法的整体性能产生积极影响)
- 特征的子集应该在给定类标签的情况下有条件地独立(条件独立的特征子集会让分类器之间的预测不太相关,进而让它们之间互相学习,能够促进个体学习者之间的一致性,进而减少泛化误差)
另外还有一种单视图的协同训练,比如生成数据的 k 个随机投影,并将这些用作 k 个不同分类器的视图。
协同正则化:同时优化了基础学习者之间的集成质量和分歧。关键思想是使用由两项组成的目标函数:一个惩罚集成做出的错误预测,另一个直接惩罚基分类器之间的不同预测。
# Boosting(提升方法)
用于集成学习,广泛用于随机森林等方法。
在 bagging 方法中,每个基础学习器都提供了一组 l 个数据点,这些数据点与替换均匀随机采样,来自原始数据集(自举)。基本分类器是独立训练的。在训练完成后,聚合它们的输出以形成集成的预测。另一方面,在 boosting 方法中,每个基础学习器都依赖于之前的基础学习器:它提供完整的数据集,但权重应用于数据点。数据点 xi 的权重基于先前基础学习器在 xi 上的性能,使得较大的权重被分配给错误分类的数据点。最终预测是作为基分类器预测的线性组合获得的。
# Unsupervised preprocessing(无监督预处理)
从未标记数据中提取有用特征,通过聚类等无监督方式预训练监督模型内部的初始参数
这与包装器方法和本质上半监督方法不同,在两个单独的阶段使用未标记的数据和标记数据。通常,无监督阶段包括来自未标记数据的样本特征的自动提取或转换(特征提取)、数据的无监督聚类(聚类然后标签)或学习过程参数的初始化(预训练)。
# Intrinsically semi-supervised methods(内在半监督方法)
直接将未标记的数据合并到学习方法的目标函数或优化过程中,直接对现有监督方法进行半监督方面的扩展
# Maximum-margin methods(最大边距方法)
Support vector machines、Gaussian processes、Density regularization(密度正则化)
# Perturbation-based methods(基于扰动的方法)
基于扰动的方法通常使用神经网络实现。由于它们直接将额外的(无监督)损失项合并到它们的目标函数中,它们相对容易地扩展到半监督设置。
第一种这样的方法是 Rasmus 等人提出的梯形网络。 (2015)。它扩展了前馈网络,通过使用网络的前馈部分作为去噪自动编码器的编码器来合并未标记的数据,添加解码器,并在成本函数中包含一项以惩罚重建成本。其基本思想是,对输入重构有用的潜在表示也可以促进类预测。(对未标注数据的重建任务,通过解码器实现,并返回相应损失)
伪集成:人们还可以扰乱神经网络模型本身,而不是显式地扰动输入数据。然后可以通过对同一输入施加扰动网络的激活与原始网络的激活之间的差异的惩罚来促进模型中的鲁棒性。Bachman等人(2014)针对这种方法提出了一个通用框架,其中扰动参数为θ的未扰动父模型以获得一个或多个子模型。在这个框架中,它们称为伪集成,扰动是从噪声分布中获得的。然后根据未扰动的父网络 fθ (x) 和噪声分布的样本 ξ 生成扰动网络 ̃fθ (x; ξ )。然后半监督成本函数由监督部分和无监督部分组成。前者捕获标记输入数据的扰动网络的损失,后者捕获未标记数据点扰动网络之间的一致性。
Mean-Teacher:
# Transductive methods(转导方法)
与归纳方法不同,转导方法不会为整个输入空间构建一个分类器。相反,他们的预测能力仅限于在训练阶段遇到的那些对象。因此,转导方法没有明显的训练和测试阶段。由于监督学习方法根据定义没有提供未标记的数据直到测试阶段,监督学习中不存在转导算法的明显类比。由于转导学习器中不存在输入空间模型,因此必须通过数据点之间的直接连接传播信息。这一观察结果自然产生了一种基于图的转导方法:如果可以定义具有相似数据点连接的图,则可以沿着该图的边缘传播信息。在实践中,我们讨论的所有转导方法要么显式基于图的,要么可以隐式理解为这样的。我们注意到,基于归纳图的方法也存在;我们在第 6.3 节中涵盖了它们。归纳和基于转导图的方法通常在流形假设上前提:基于数据点之间的局部相似性构建的图提供了潜在高维输入数据的低维表示。基于转导图的方法一般包括三个步骤:图构建、图加权和推理。在第一步中,对象集 X 用于构建图,其中每个节点代表一个数据点,成对的相似数据点由一条边连接。在第二步中,对这些边进行加权,以表示各个数据点之间的成对相似度的程度。第三步,该图用于将标签分配给未标记的数据点。第7节详细讨论了执行这三个步骤的不同方法。